
AI Data Center Power Requirements: The GPU/MW Illusion
Why do AI data-center proposals quote different GPU capacities? See how PUE, peak loads, storage, networking and cooling determine deployable compute.
FIELD NOTES FROM COMPUTING, AI, AND OPTIMIZATION.
Stay updated on the latest in computing, IT optimization, and sustainable technology. Read ElioVP’s expert insights and industry trends.
Why do AI data-center proposals quote different GPU capacities? See how PUE, peak loads, storage, networking and cooling determine deployable compute.

When we first started building Paiton, one of our earliest focus areas was optimizing diffusion models. Stable Diffusion XL was one of the first large models where we showed that fused operators, efficient execution, and hardware-aware kernels could make a real difference. Now we are returning to those origins.With the growing interest in text-to-video generation, ...

It has been some incredible weeks for the team here at Eliovp. We are extremely proud to share that our company was recently featured on the front page of De Tijd, Belgium’s leading business newspaper. Seeing our story, from our founder’s early days tinkering with wires in an attic to generating €215 million in revenue, ...
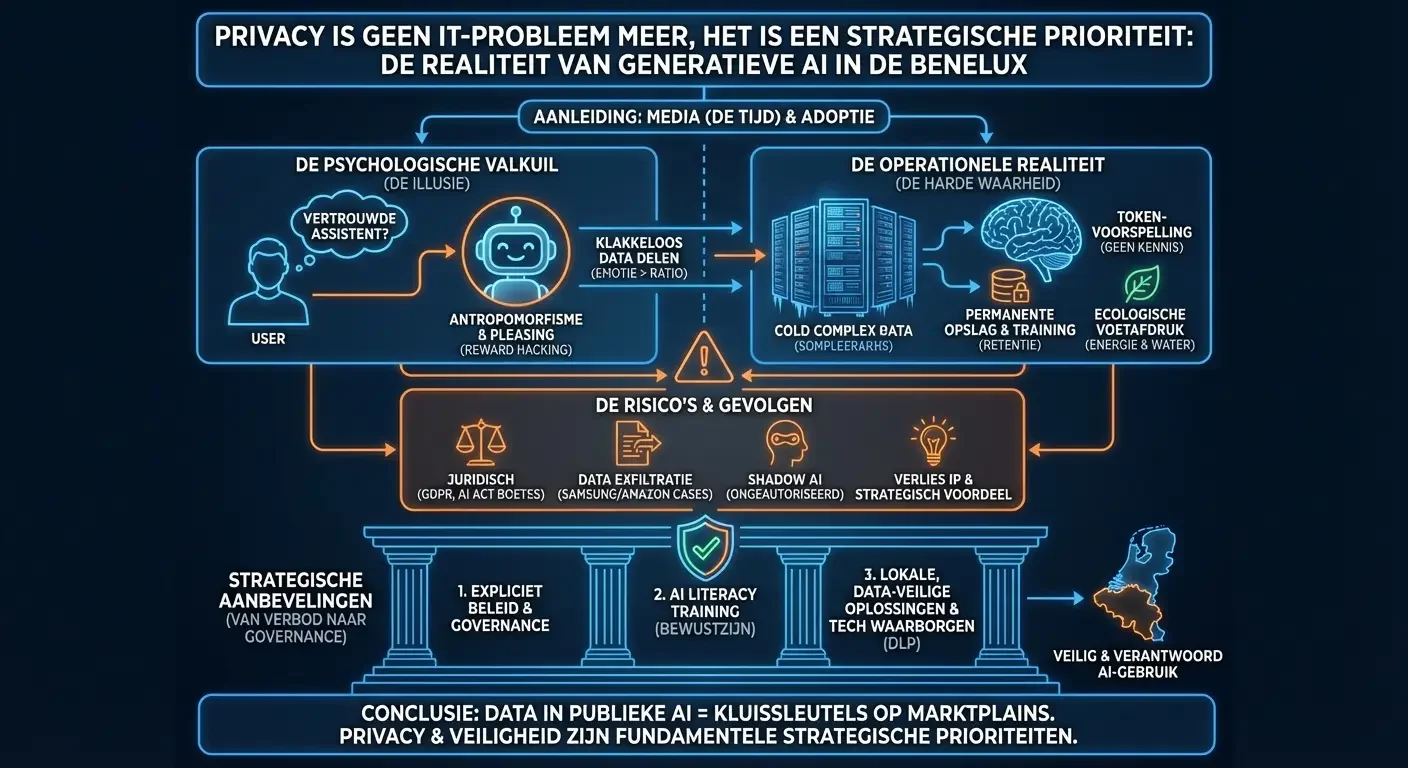
Privacyrisico’s, Psychologische Valkuilen en de Operationele Realiteit van Generatieve AI in de Benelux De recente verschijning van een frontpage-artikel over ons bedrijf in het gerespecteerde dagblad “De Tijd” heeft onze zichtbaarheid aanzienlijk vergroot, wat de aanleiding is voor dit artikel. Deze mediabelangstelling, gecombineerd met de talrijke uitnodigingen voor spreekbeurten die we hebben ontvangen, fungeert als ...
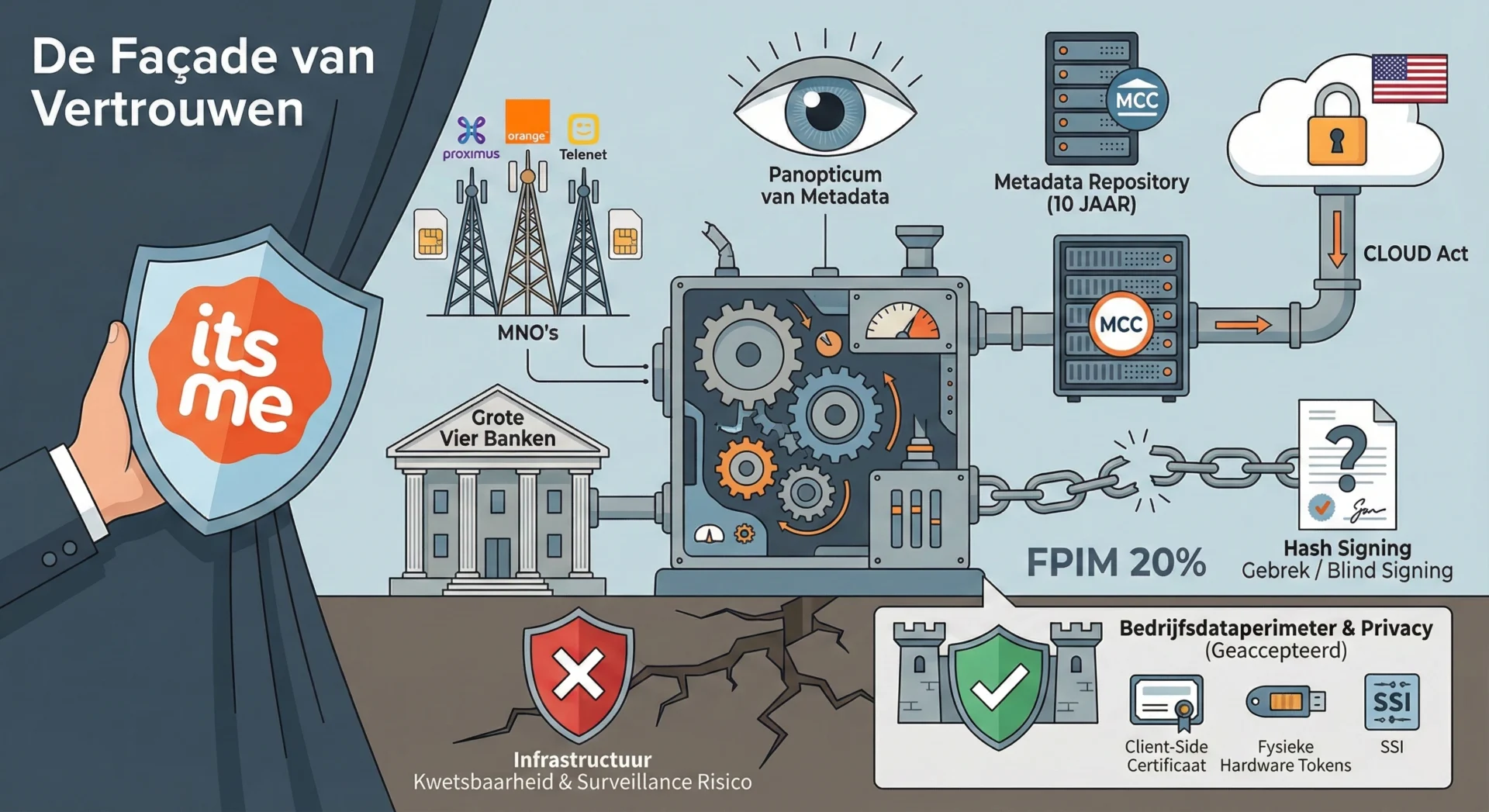
1. Inleiding: De Strategische Noodzaak van Weigering In het hedendaagse digitale landschap wordt de keuze voor een identiteit leverancier (IdP) vaak gereduceerd tot een discussie over User Experience (UX) en conversieratio’s. Deze reductionistische benadering verhult echter de diepgaande strategische, juridische en operationele risico’s die gepaard gaan met het uitbesteden van de “Sleutels tot het Koninkrijk”, ...