
Paiton Returns to Its Diffusion Roots: Optimizing Wan2.2-T2V-A14B on AMD MI355X

When we first started building Paiton, one of our earliest focus areas was optimizing diffusion models. Stable Diffusion XL was…
When we first started building Paiton, one of our earliest focus areas was optimizing diffusion models. Stable Diffusion XL was one of the first large models where we showed that fused operators, efficient execution, and hardware-aware kernels could make a real difference. Now we are returning to those origins.With the growing interest in text-to-video generation, we have added support for…

It has been some incredible weeks for the team here at Eliovp. We are extremely proud to share that our company was recently featured on the front page of De Tijd, Belgium’s leading business newspaper. Seeing our story, from our founder’s early days tinkering with wires in an attic to generating €215 million in revenue, printed in bold on the…
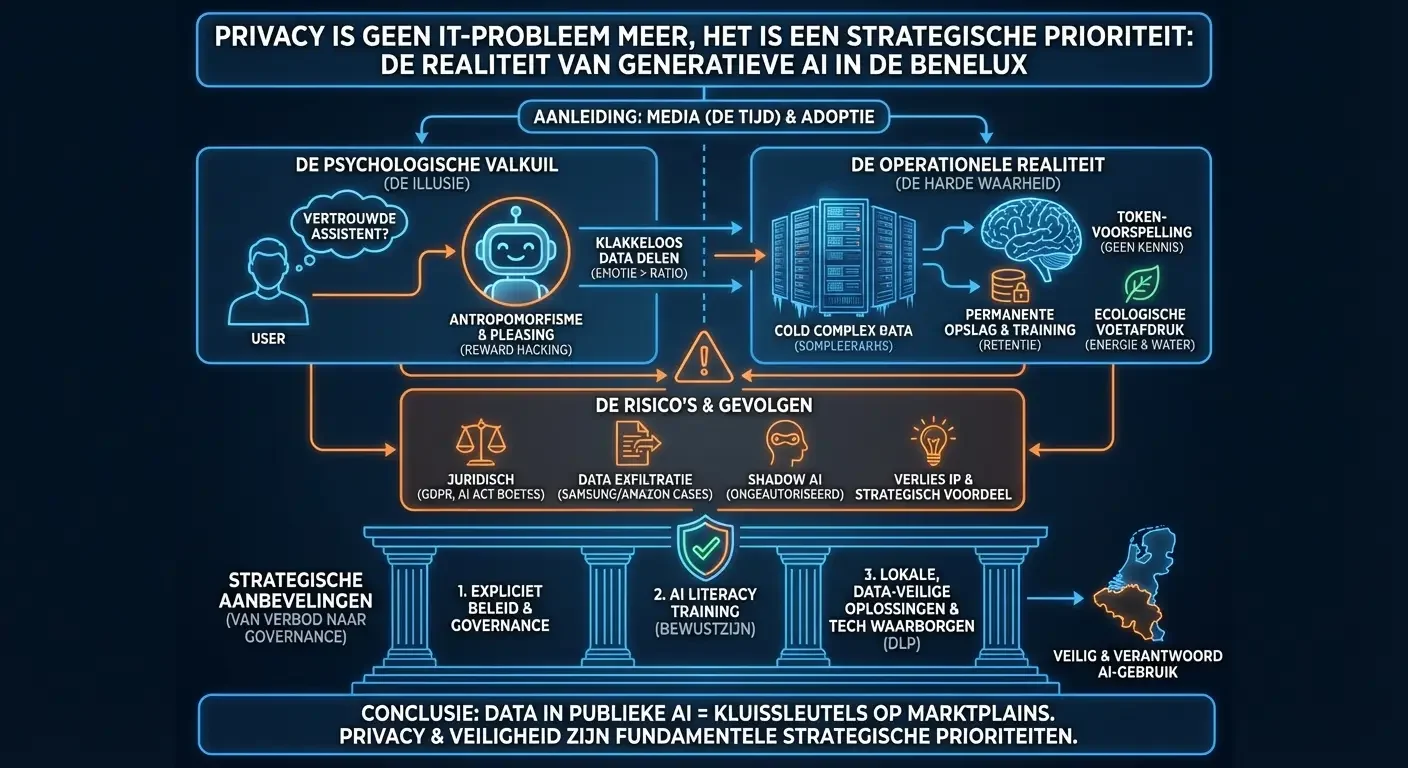
Privacyrisico's, Psychologische Valkuilen en de Operationele Realiteit van Generatieve AI in de Benelux De recente verschijning van een frontpage-artikel over ons bedrijf in het gerespecteerde dagblad "De Tijd" heeft onze zichtbaarheid aanzienlijk vergroot, wat de aanleiding is voor dit artikel. Deze mediabelangstelling, gecombineerd met de talrijke uitnodigingen voor spreekbeurten die we hebben ontvangen, fungeert als een katalysator voor de massale…
When we first started building Paiton, one of our earliest focus areas was optimizing diffusion models. Stable Diffusion XL was…
It has been some incredible weeks for the team here at Eliovp. We are extremely proud to share that our…
Privacyrisico's, Psychologische Valkuilen en de Operationele Realiteit van Generatieve AI in de Benelux De recente verschijning van een frontpage-artikel over…
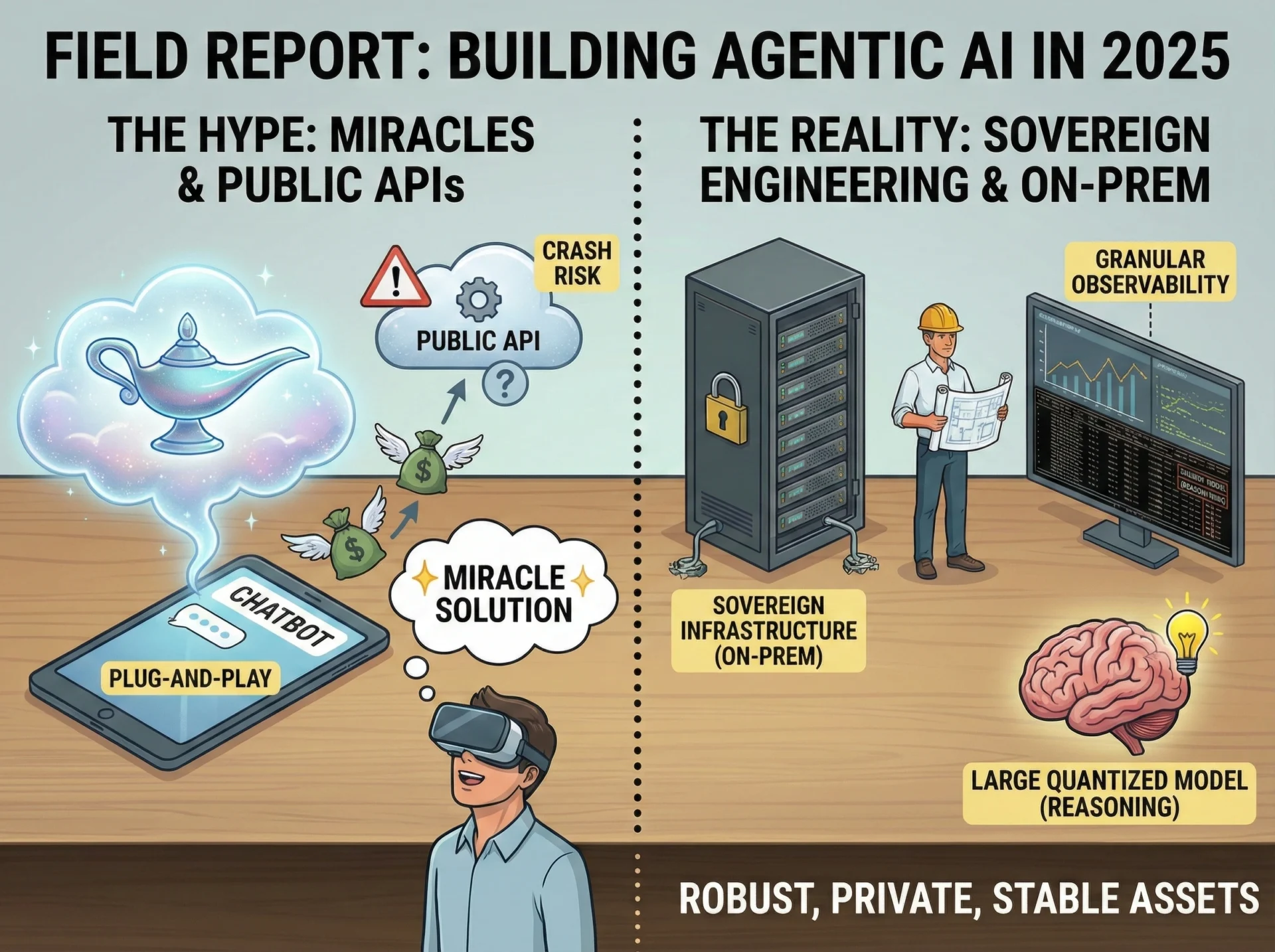
Van Hype naar Soevereine Infrastructuur English version Samenvatting Het verhaal rond “Agentic AI” in 2025 wordt gekenmerkt door een scherp…