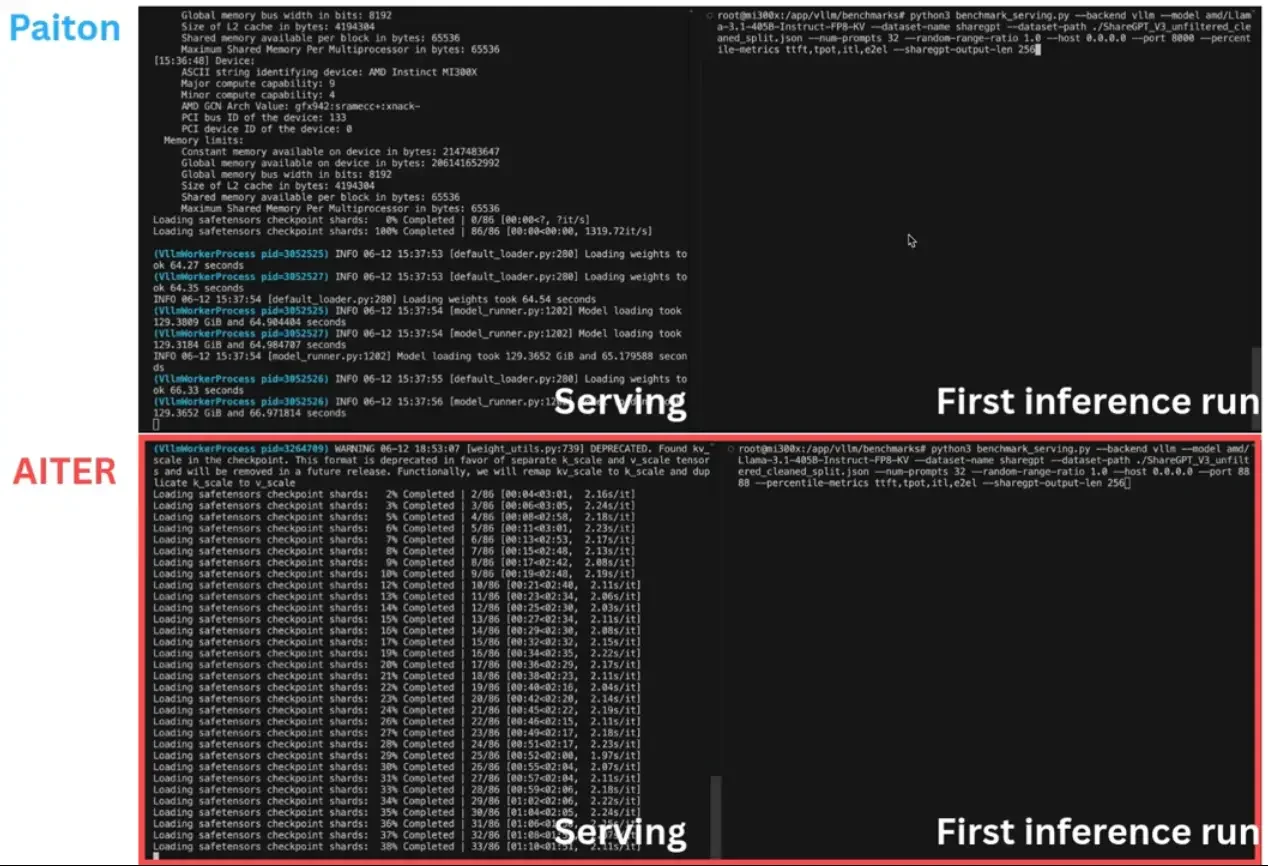
With Paiton, we're not merely pursuing peak inference speeds, we're fundamentally reshaping the entire lifecycle of large language model (LLM) deployment. Our latest endeavor pairs AMD's cutting-edge MI300X GPUs with the colossal Llama-3.1-405B-Instruct-FP8-KV model, achieving groundbreaking milestones: Visual Demonstration: Startup Speed Showcase We're excited to share a visual demonstration of Paiton's revolutionary startup performance. Watch below how Paiton transforms a…

The world of AI is moving at an unprecedented pace, and efficient inference is key to deploying powerful models in real-world applications. At Eliovp, we've consistently pushed the boundaries of AI performance, as highlighted in our previous blogs showcasing significant inference speedups when benchmarking with fp16/bf16. Now, we're thrilled to announce a further significant leap forward: Paiton now achieves superior…

As large language models (LLMs) become a foundational part of modern applications, picking the right server for deployment is more important than ever. Whether you're an enterprise scaling up inference, a startup optimizing for cost, or a researcher pushing throughput boundaries. This blog compares two high-profile server setups and two not so high-profile setups which are usually not used as…