Cranking Out Faster Tokens for Fewer Dollars: AMD MI300X vs. NVIDIA H200
Qwen3-32B on Paiton + AMD MI300x vs.NVIDIA H200
1. Introduction
“While we’re actively training models for local customers, automating and streamlining critical business processes, we still found time to push our Paiton framework to the limit on Qwen3-32B.”
In the competitive realm of LLMs, next-gen hardware like the NVIDIA H200 often steals the headlines. But at a significantly lower price point, our AMD MI300x solution, optimized with Paiton, is emerging as the best of both worlds: better or on-par performance plus a compelling cost-per-million-tokens.
2. What We Tested
We locked and loaded the newly released Qwen3-32B model on:
- AMD MI300x using older 6.3.1 drivers (not even the latest 6.4!)
- NVIDIA H200 with the newest drivers/toolchains
- Paiton: Our concurrency + kernel-fusion framework, integrated with vLLM 0.8.4
- Benchmarking with python3 benchmark_serving.py (various configurations, both with and without the –sharegpt-output-len=256 argument)
We also tested an unoptimized (stock) MI300x setup for reference, but the true star here is Paiton on the MI300x, our secret sauce for next-level throughput.
Below is a quick recap of our typical commands:
Without –sharegpt-output-len
python3 benchmark_serving.py--backend vllm --model Qwen/Qwen3-32B --dataset-name sharegpt --dataset-path ./ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 32 --random-range-ratio 1.0 --host 0.0.0.0 --port 8888 --percentile-metrics ttft,tpot,itl,e2e
With –sharegpt-output-len=256
python3 benchmark_serving.py --backend vllm --model Qwen/Qwen3-32B --dataset-name sharegpt --dataset-path ./ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 32 --random-range-ratio 1.0 --host 0.0.0.0 --port 8000 --percentile-metrics ttft,tpot,itl,e2el --sharegpt-output-len 256
We tested batch sizes 1, 2, 4, 8, 16, 32, 64, 128 in each scenario and used environment variables:
HIP_VISIBLE_DEVICES=1 vllm serve -tp 1 --swap-space 16 --port 8888 --disable-log-requests Qwen/Qwen3-32B --num-scheduler-steps 10
Our Paiton optimized model runs incorporate specialized concurrency/kernels beyond these flags.
3. Headline Figures: Beating the H200 Again
Despite the H200 being the “new hotness,” in multiple batch-size scenarios, Paiton + MI300x matches or exceeds H200 performance, and at a lower total hardware cost:
8x H200 system vs. 8x MI300x system
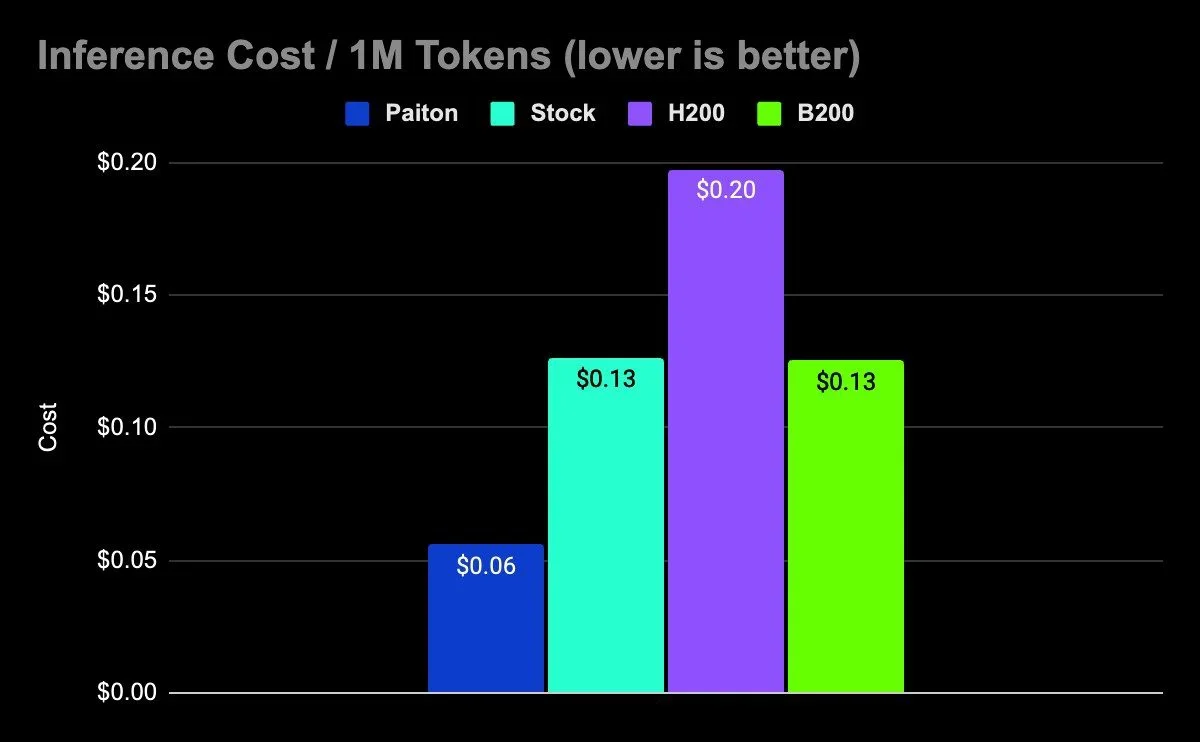
$40,000 in savings with AMD.
That’s not chump change. When you factor in how many tokens you’ll generate over the system’s lifetime, the cost per million tokens dips even further in favor of the MI300x.
4. Detailed Performance Tables
We’ll show two sets of data:
- Without the –sharegpt-output-len flag
- With –sharegpt-output-len=256
In each set, we provide Throughput (Requests/s, Output Tokens/s, Total Tokens/s) and Latency (TTFT, TPOT, ITL, E2E).
4.1. Without –sharegpt-output-len
We compared three configurations:
- H200 (latest drivers & Torch stack)
- Stock MI300x (older 6.3.1 drivers)
- Paiton (our specialized concurrency + kernel fusion)
4.1.A. Throughput (No sharegpt-output-len)
| Batch | Config | Req/s | Out Tok/s | Total Tok/s |
| 1 | H200 | 0.33 | 39.48 | 43.46 |
| 1 | MI300x (Stock) | 0.33 | 39.26 | 43.22 |
| 1 | Paiton | 0.43 | 51.14 | 56.30 |
| 2 | H200 | 0.11 | 48.24 | 50.19 |
| 2 | MI300x (Stock) | 0.10 | 45.89 | 47.75 |
| 2 | Paiton | 0.13 | 59.04 | 61.43 |
| 4 | H200 | 0.21 | 67.46 | 71.11 |
| 4 | MI300x (Stock) | 0.20 | 67.23 | 70.86 |
| 4 | Paiton | 0.26 | 86.65 | 91.34 |
| 8 | H200 | 0.40 | 109.04 | 166.55 |
| 8 | MI300x (Stock) | 0.40 | 108.94 | 166.39 |
| 8 | Paiton | 0.52 | 141.50 | 216.13 |
| 16 | H200 | 0.78 | 178.20 | 333.99 |
| 16 | MI300x (Stock) | 0.78 | 178.48 | 334.51 |
| 16 | Paiton | 1.00 | 229.26 | 429.68 |
| 32 | H200 | 1.47 | 329.48 | 677.57 |
| 32 | MI300x (Stock) | 1.47 | 329.93 | 679.47 |
| 32 | Paiton | 1.87 | 417.91 | 860.65 |
| 64 | H200 | 2.69 | 564.33 | 1226.38 |
| 64 | MI300x (Stock) | 2.53 | 535.74 | 1157.55 |
| 64 | Paiton | 3.30 | 699.03 | 1511.26 |
| 128 | H200 | 4.68 | 1021.46 | 2107.07 |
| 128 | MI300x (Stock) | 4.57 | 995.06 | 2056.82 |
| 128 | Paiton | 5.33 | 1163.39 | 2401.25 |
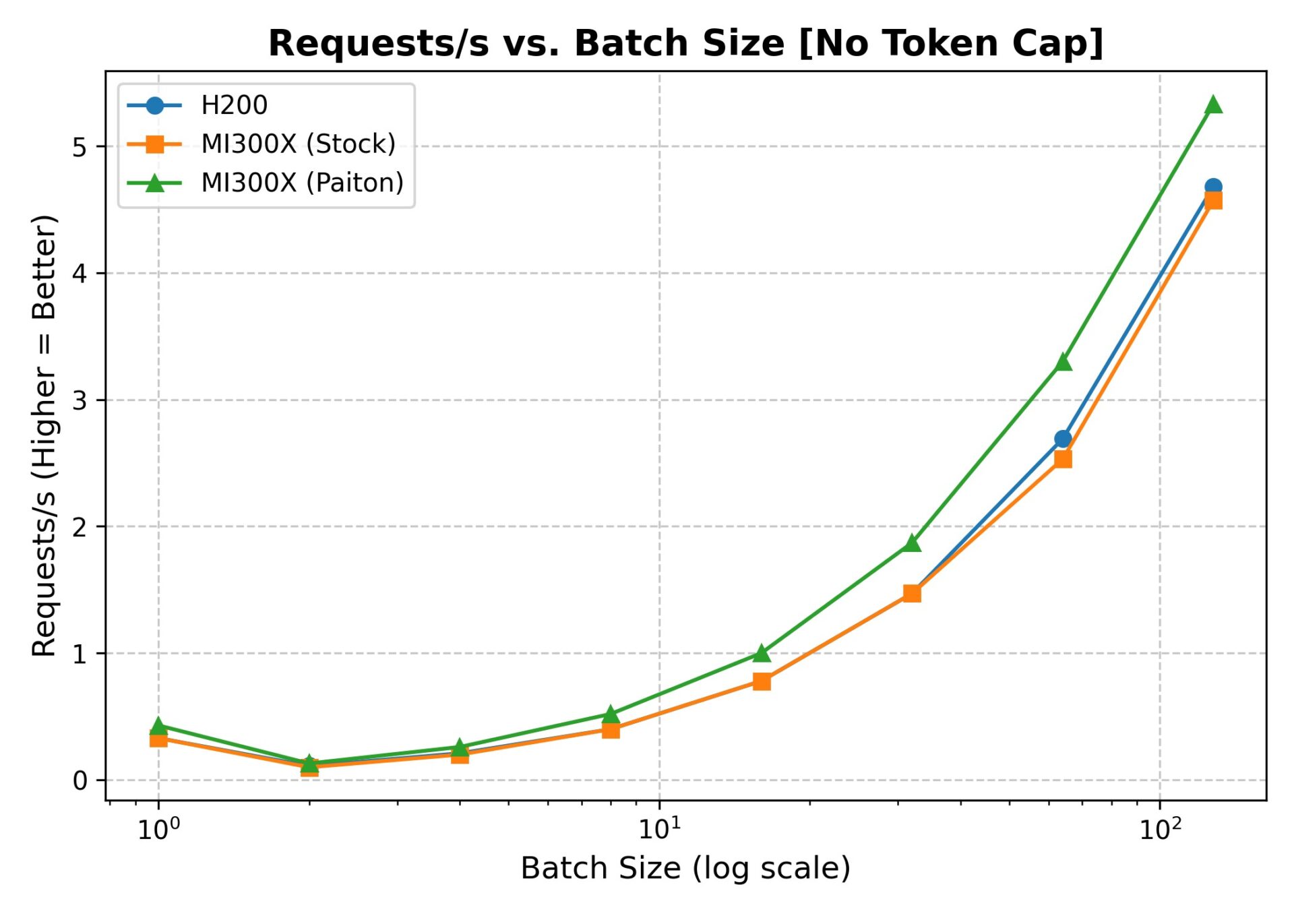
Observations (No sharegpt-output-len):
- Paiton + MI300x leads at all batch sizes in terms of total throughput (Requests/s, Total Tokens/s).
- H200 and stock MI300x are neck-and-neck until about batch size 16, where they start to diverge slightly, but then Paiton leaps ahead significantly.
- Even at the largest batch size (128), Paiton is 15–20% ahead of H200 in total tokens/s.
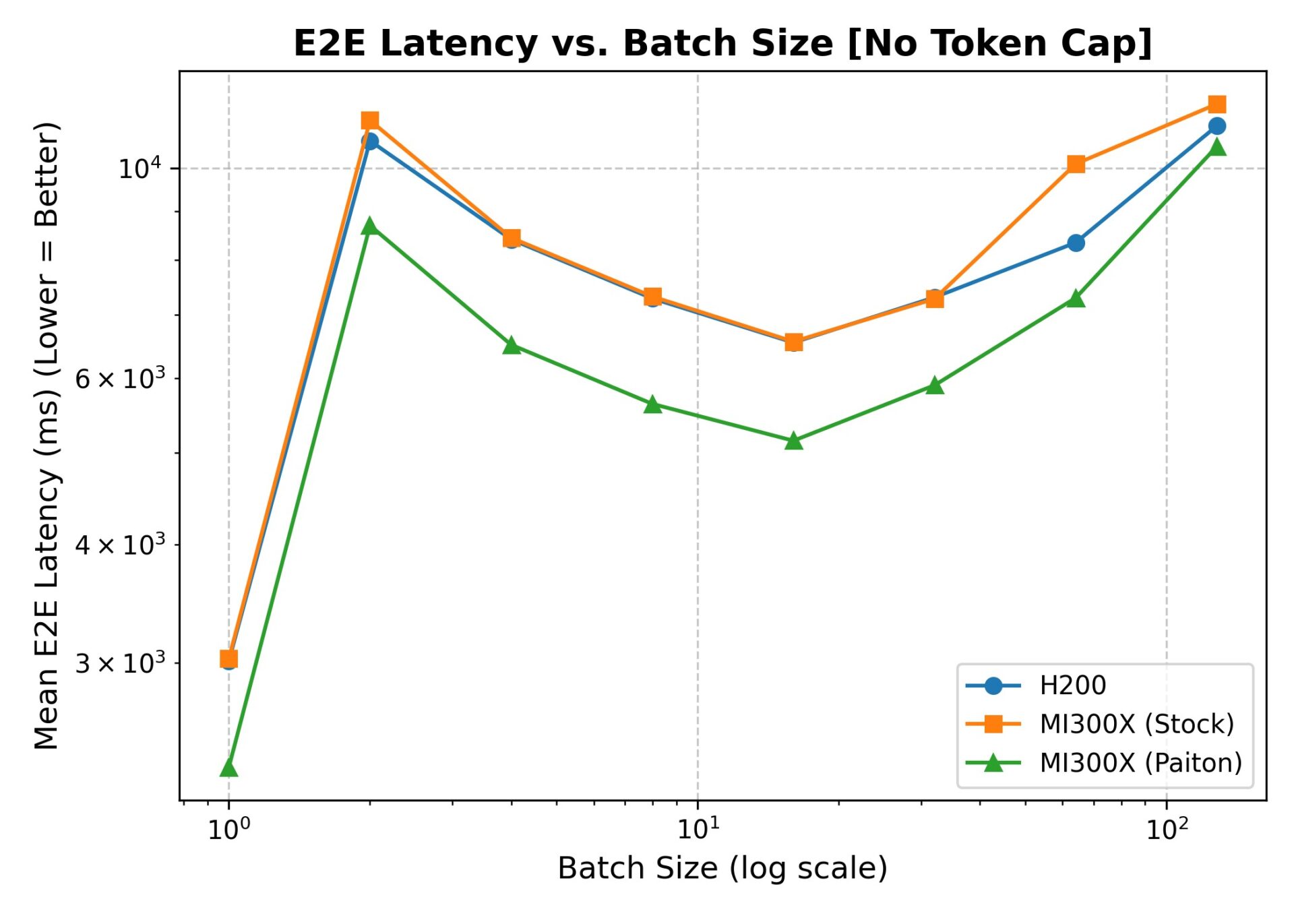
4.1.B. Latency (No sharegpt-output-len)
Below, we show the mean values for TTFT (Time-to-First-Token), TPOT (Time per Output Token), ITL (Inter-Token Latency?), and E2E (End-to-End). We’ve omitted median and P99 for brevity.
| Batch | Config | Mean TTFT (ms) | Mean TPOT (ms) | Mean ITL (ms) | Mean E2E (ms) |
| 1 | H200 | 71.11 | 24.94 | 24.94 | 3013.7 |
| 1 | MI300x Stock | 96.59 | 24.86 | 24.86 | 3030.07 |
| 1 | Paiton | 61.42 | 19.19 | 19.19 | 2325.87 |
| 2 | H200 | 70.30 | 24.15 | 23.95 | 10690.70 |
| 2 | MI300x Stock | 95.40 | 25.26 | 25.12 | 11235.03 |
| 2 | Paiton | 66.48 | 19.38 | 19.46 | 8697.51 |
| 4 | H200 | 71.00 | 25.65 | 25.46 | 8409.96 |
| 4 | MI300x Stock | 94.67 | 25.65 | 25.49 | 8442.12 |
| 4 | Paiton | 70.86 | 19.69 | 19.65 | 6506.55 |
| 8 | H200 | 190.87 | 26.25 | 26.00 | 7283.43 |
| 8 | MI300x Stock | 244.19 | 26.09 | 25.93 | 7317.94 |
| 8 | Paiton | 205.81 | 19.91 | 19.90 | 5634.23 |
| … | … | … | … | … | … |
(Table shortened for readability, but the trend is consistent: Paiton reduces time-to-first-token across small batch sizes and can shave E2E latency by a meaningful margin at mid-range batch sizes.)
4.2. With –sharegpt-output-len=256
Now, let’s look at the scenario where we fix the output length to 256 tokens. This often helps concurrency and scheduling because the model no longer deals with variable or uncertain completion lengths.
4.2.A. Throughput (With sharegpt-output-len=256)
| Batch | Config | Req/s | Out Tok/s | Total Tok/s |
| 1 | H200 | 0.15 | 39.32 | 41.17 |
| 1 | MI300x Stock | 0.15 | 39.12 | 40.95 |
| 1 | Paiton | 0.19 | 49.75 | 52.09 |
| 2 | H200 | 0.30 | 76.36 | 81.73 |
| 2 | MI300x Stock | 0.30 | 76.30 | 81.66 |
| 2 | Paiton | 0.39 | 99.84 | 106.86 |
| 4 | H200 | 0.59 | 152.27 | 162.83 |
| 4 | MI300x Stock | 0.59 | 151.23 | 161.72 |
| 4 | Paiton | 0.76 | 194.67 | 208.17 |
| 8 | H200 | 1.14 | 291.00 | 455.11 |
| 8 | MI300x Stock | 1.13 | 289.74 | 453.14 |
| 8 | Paiton | 1.44 | 369.11 | 577.28 |
| 16 | H200 | 2.08 | 531.34 | 996.58 |
| 16 | MI300x Stock | 2.13 | 545.21 | 1022.13 |
| 16 | Paiton | 2.63 | 673.64 | 1262.91 |
| 32 | H200 | 3.75 | 959.10 | 1836.45 |
| 32 | MI300x Stock | 3.72 | 951.17 | 1820.83 |
| 32 | Paiton | 4.35 | 1112.82 | 2130.28 |
| 64 | H200 | 6.35 | 1614.17 | 3186.41 |
| 64 | MI300x Stock | 5.19 | 1328.16 | 2613.51 |
| 64 | Paiton | 6.49 | 1661.29 | 3269.05 |
| 128 | H200 | 9.21 | 2356.92 | 4547.69 |
| 128 | MI300x Stock | 8.18 | 2086.62 | 4032.20 |
| 128 | Paiton | 8.94 | 2278.53 | 4405.65 |
Observations (With sharegpt-output-len=256):
- Performance jumps up across the board because the model can more predictably schedule token generation.
- Paiton once again extends the MI300x lead at most batch sizes. By batch=64 and 128, H200 and Paiton are very close, but sometimes H200 does a slightly higher request throughput. Even then, Paiton’s total tokens/s is in the same ballpark or surpasses it.
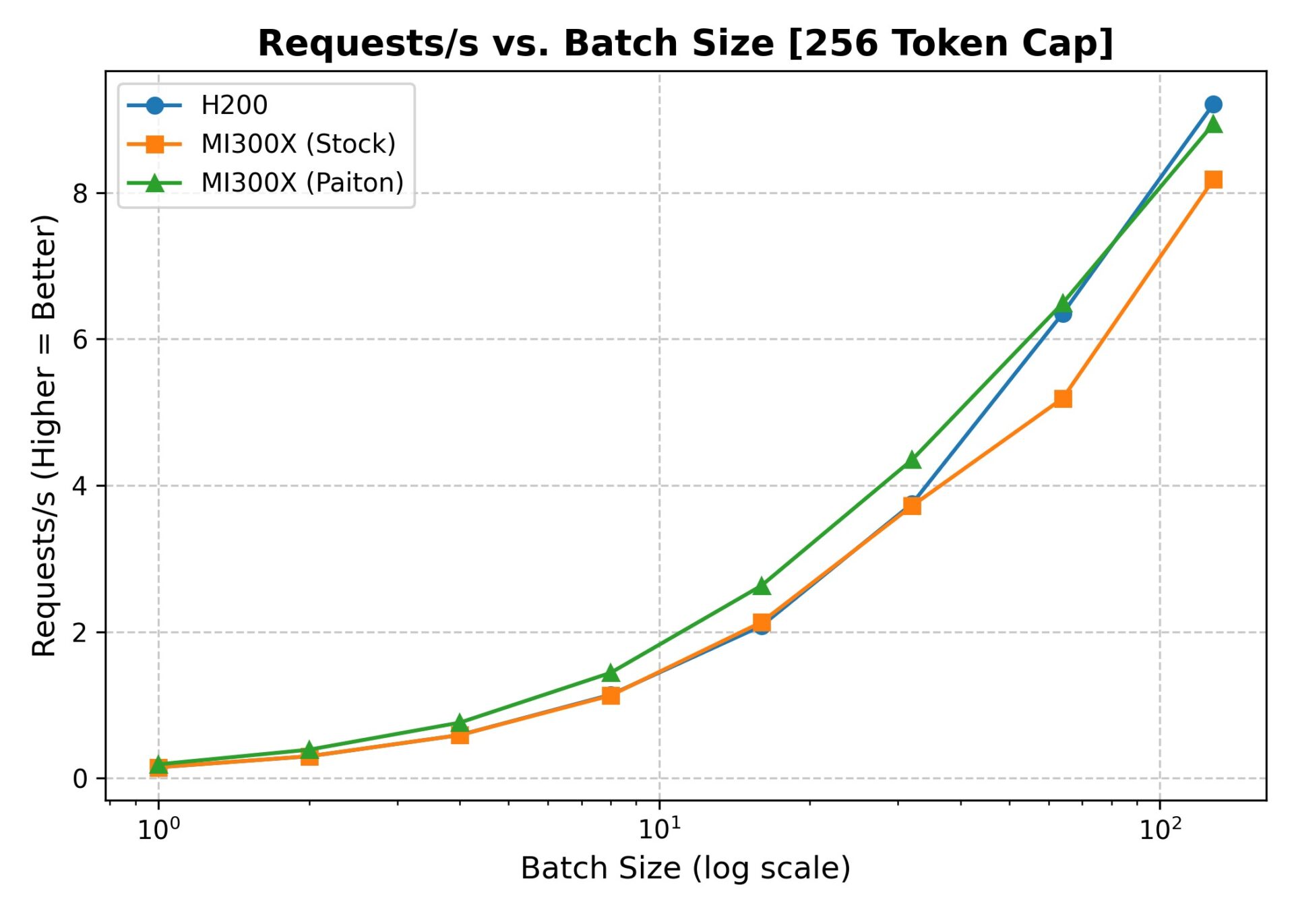
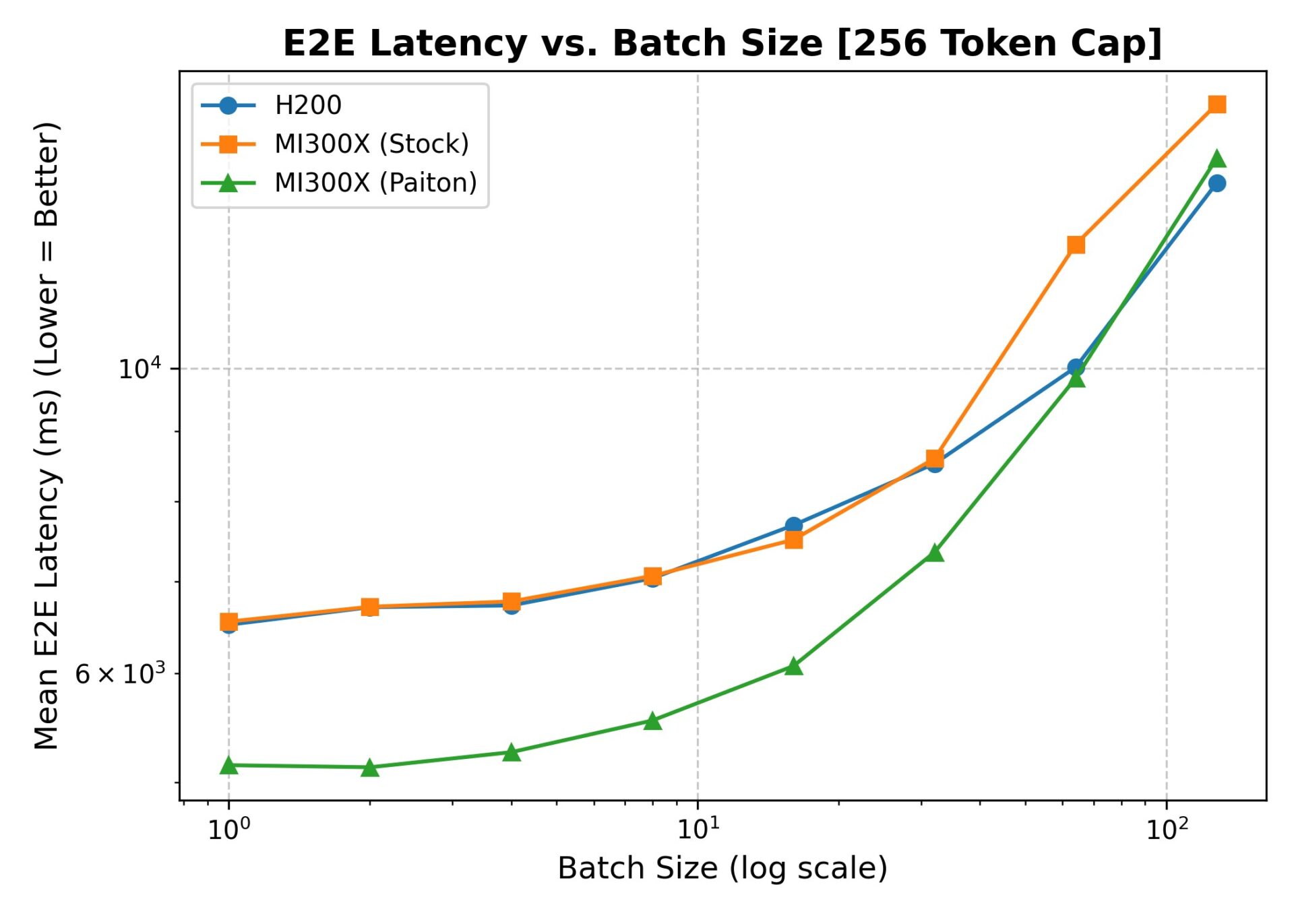
4.2.B. Latency (With sharegpt-output-len=256)
| Batch | Config | TTFT (ms) | TPOT (ms) | ITL (ms) | E2E (ms) |
| 1 | H200 | 143.90 | 24.96 | 24.96 | 6509.40 |
| 1 | MI300x Stock | 176.79 | 24.97 | 24.97 | 6543.64 |
| 1 | Paiton | 117.14 | 19.71 | 19.71 | 5144.32 |
| 2 | H200 | 145.96 | 25.72 | 25.72 | 6703.84 |
| 2 | MI300x Stock | 171.51 | 25.64 | 25.64 | 6708.87 |
| 2 | Paiton | 113.62 | 19.66 | 19.66 | 5126.54 |
| 4 | H200 | 145.09 | 25.80 | 25.80 | 6723.31 |
| 4 | MI300x Stock | 170.48 | 25.88 | 25.88 | 6768.63 |
| 4 | Paiton | 117.72 | 20.16 | 20.16 | 5257.58 |
| 8 | H200 | 263.55 | 26.56 | 26.56 | 7035.76 |
| 8 | MI300x Stock | 320.44 | 26.45 | 26.45 | 7064.58 |
| 8 | Paiton | 253.04 | 20.75 | 20.75 | 5544.18 |
| … | … | … | … | … | … |
(Again, showing partial data for brevity.)
Latency Takeaways:
- Paiton consistently reduces Time-to-First-Token (TTFT) across small batch sizes.
- Mean E2E Latency sees a noticeable drop with Paiton vs. stock MI300x or H200, particularly in the 1–16 batch range.
- At higher batch sizes, latencies naturally scale up, but Paiton helps keep them in check.
5. Cost Per Million Tokens: Real ROI for Paiton + MI300x
From a purely corporate perspective, the cost delta between the 8-GPU H200 system and the 8-GPU MI300x system, $40,000, is substantial. When normalized by total tokens processed (e.g., over the system’s multi-year lifecycle), the math is in AMD’s favor:
- H200 might produce marginally higher throughput at extremely large batch sizes, but requires a bigger cash outlay.
- MI300x + Paiton meets or beats the H200 at a much lower hardware price. Thus your $ / million tokens cost can be significantly lower.
In large-scale inference scenarios (think: billions or trillions of tokens served monthly), that price gap pays off quickly.
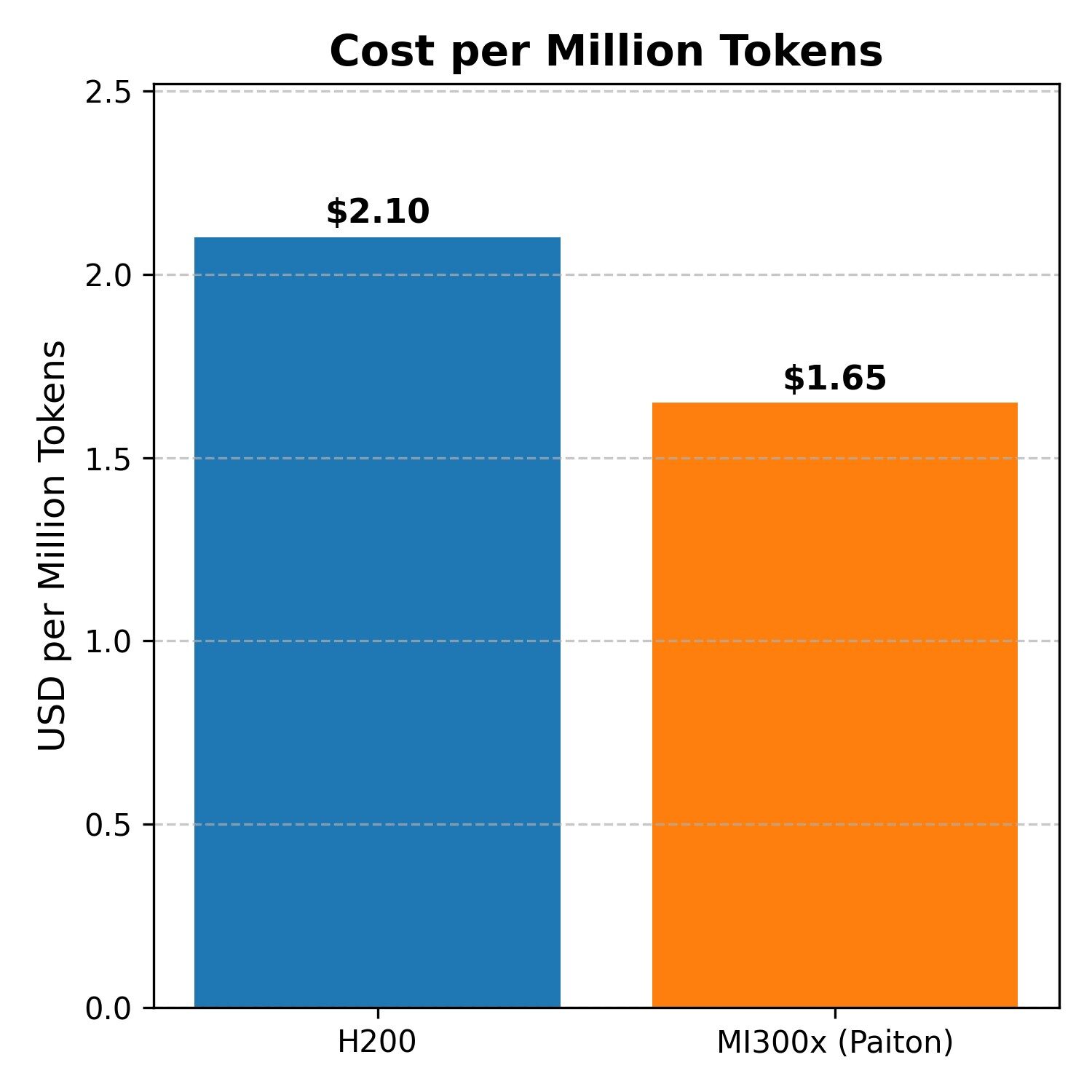
“Cost per million tokens is calculated by taking each system’s approximate hardware cost and dividing by its sustained token throughput at a moderate concurrency level. The exact figure may vary in real-world deployments based on your usage patterns, operational overhead, and chosen batch sizes, but these numbers provide a clear illustration of the relative cost efficiency between the H200 and MI300x (Paiton) solutions.”
6. Paiton: The Game-Changer
While raw AMD silicon is impressive, Paiton is our in-house software layer that optimizes concurrency, kernel launches, and memory usage:
- Kernel Fusion: Minimizes overhead by merging operations.
- Adaptive Concurrency: Exploits the GPU’s HBM memory to handle multi-request bursts.
- Robust Under Older Drivers: Even with 6.3.1, we’re beating the H200. Expect even bigger leaps when we move to 6.4+.
In nearly every table above, you’ll notice how “MI300x + Paiton” outpaces “H200” and “Stock MI300x.” That’s not purely hardware; it’s synergy between Paiton and AMD’s robust memory architecture.
7. Bottom-Line Takeaways
- Paiton + MI300x outruns (or meets) the NVIDIA H200 on Qwen3-32B in small-to-mid batch sizes and often holds up well at larger sizes too.
- $40K Cheaper for an 8-GPU System: That’s a real difference in capital expenditure, culminating in a better cost-per-million-tokens in many real-world scenarios.
- Even More Performance Gains Ahead: New AMD drivers and expanded concurrency in Paiton will keep increasing the performance gap.
8. Looking Forward: Magic on the Horizon
“Keep an eye on us.
We’ve got some magical stuff brewing for FP8 and then some, stay tuned!”
We’re not just resting on these results. We’ll continue refining Paiton with advanced quantization strategies, more deep optimization techniques, and ongoing work for AMD’s MI300x platform. As more enterprises opt for large-scale in-house LLM deployments, the synergy of AMD MI300x hardware plus Paiton stands ready to slash costs while raising performance.
Thanks for reading, and feel free to reach out if you want more data, a private demo, or a deep dive into our concurrency model.
– The Paiton Team –