MI300X vs H200 vs RX 7900 XTX vs Tenstorrent n300s with vLLM
As large language models (LLMs) become a foundational part of modern applications, picking the right server for deployment is more important than ever. Whether you’re an enterprise scaling up inference, a startup optimizing for cost, or a researcher pushing throughput boundaries. This blog compares two high-profile server setups and two not so high-profile setups which are usually not used as servers in a DC, each with unique GPU/accelerator hardware and using vLLM.
We’ll compare:
- AMD MI300X
- NVIDIA H200
- Tenstorrent n300s
- AMD RX 7900 XTX
While comparing the RX 7900 XTX to data center-class GPUs may seem unfair, it’s important to recognize its versatility. As a multi-purpose GPU capable of both high-end gaming and AI development, it offers a practical advantage: you can use the same system for development and leisure, making it a compelling option for individual developers, small teams, or data centers that want to dynamically switch between gaming and AI workloads based on demand.
That said, if we’re being honest, we’re including the RX 7900 XTX primarily because we already have it available and were curious to see how it stacks up against dedicated data center hardware.
The other odd one in this race is the Tenstorrent system, it’s been showing great potential and promise and it caught my eye about 3 years ago. We were very keen to test this system against its giant competitors because it would add some variety and excitement to the current two main players in AI (sorry Intel).
GPU Specs (as of Q2 2025)
| Accelerator | Architecture | VRAM | Memory Type | TDP | Approx Price (USD) |
| AMD MI300X | CDNA3 | 192 GB | HBM3 | 750W | ~$15,000 |
| NVIDIA H200 | Hopper | 141 GB | HBM3e | 700W | ~$30,000 |
| AMD RX 7900 XTX | RDNA3 | 24 GB | GDDR6 | 355W | ~$1,000 |
| Tenstorrent n300s | Custom RISC-V | 24 GB | GDDR6 | 300W | ~$1,399 |
Note: These values reflect typical specs for each GPU/accelerator. Actual performance can vary based on system integration and workload characteristics. (e.g., CPU, motherboard, cooling). The focus here is on the GPU/accelerator as the main differentiator.
Power Measurement Method
This comparison was challenging because accurate per-GPU cost per million tokens for MI300X and H200 is difficult to estimate since individual GPU prices are not publicly available. Therefore, we calculated cost per million tokens using the full system price and approximate power consumption. This approach makes more sense, in real deployments, system-level costs (power, hardware, infrastructure) contribute to operational expenses beyond just the GPU. To account for the full system, we multiplied the measured token throughput and single GPU power consumption by the number of GPUs in the server and then added that to the total system power consumption, effectively spreading system cost and power across all GPUs under the assumption of full utilization. Note that these values represent idle or estimated power consumption only and do not account for additional components or increased draw under full system utilization.
The idle power consumption for the H200 system was not directly measured, but an estimate was obtained from an article, which suggests that the system typically consumes around 2200W when idle. For more details, refer to the ServeTheHome article.
The idle power consumption of the RX 7900 system could not be directly measured and was instead estimated to be around 400W.
The power consumption values for other systems were measured using the ipmitool tool.
Server Configurations and Pricing
| Server | CPU | RAM | Storage | Cooling | # of GPUs | Idle System Power (Est.) | System Price (USD) |
| A+ Server 8125GS-TNMR2 | 2x EPYC 9654 | 1536GB | 4TB NVMe | Air | 8 | ~2400W | ~$260,564 |
| SuperServer 821GE-TNHR | 2x Intel Xeon Platinum 8468H | 1536GB | 4TB NVMe | Air | 8 | ~2200W | ~$307,336 |
| DIY AMD Workstation | Ryzen 9 7950X | 64GB | 2TB NVMe | Air | 2 | ~400W | ~$3,500 |
| Tenstorrent Loudbox | 2x Intel® Xeon® Silver 4309Y | 512GB | 4TB NVMe | Passive | 4 | ~700W | $12,000 |
Note: Configurations are representative. Real-world builds may vary depending on components, vendors, and integration costs. The prices here are found via www.thinkmate.com
Benchmark Setup
Note: All benchmarks were run using a single GPU or accelerator card per system to ensure a fair comparison across different hardware classes.
- Framework: vLLM (paged attention + continuous batching)
- Model: meta-llama/Meta-Llama-3-8B-Instruct
- Workload: Concurrent prompts, batch size 32, fixed output length of 256 tokens
- Dataset: ShareGPT
- Metrics: Tokens/sec (throughput) and cost-performance
vLLM Benchmark Results (Batch Size 32 Only)
| Server | # of GPUs | Tokens/sec per GPU | System Tokens/sec |
| AMD MI300X | 8 | 7003.10 | 56,024.8 |
| NVIDIA H200 | 8 | 8192.08 | 65,536.64 |
| AMD RX 7900 XTX(*) | 2 | 1113.59 | 2227.18 |
| Tenstorrent Loudbox | 4 | 1314.0 | 5256.0 |
Note: We encountered out-of-memory (OOM) errors when the model context length was 131072 with the AMD RX 7900 XTX. It was lowered to 22048, which is a significant change.
Cost per Million Tokens
Note: For the simplicity of comparison, we are using a 3-year lifespan (26280 hours). Power costs are calculated with a rate of $0.10 per kWh.
The calculation used to get the cost per 1M tokens can be seen and reviewed here:
Assuming a 3 year depreciation and full system+GPU utilization
AMD MI300X Server:
Assuming 2400W idle power consumption and 8 GPUs fully utilized at 750W, the total would be 8.4kW
- System Tokens/sec: 7003.10 tokens/sec/GPU * 8 GPUs = 56,024.8 tokens/sec
- Tokens per hour: 56,024.8 tokens/sec * 3600 sec/hour = 201,689,280 tokens/hour
- Cost per hour: $260,564 / 26280 hours + 8.4kW * $0.10/kWh = $10.76
- Cost per 1M tokens: $10.76 / (201,689,280 / 1,000,000) = $0.053 per 1M tokens
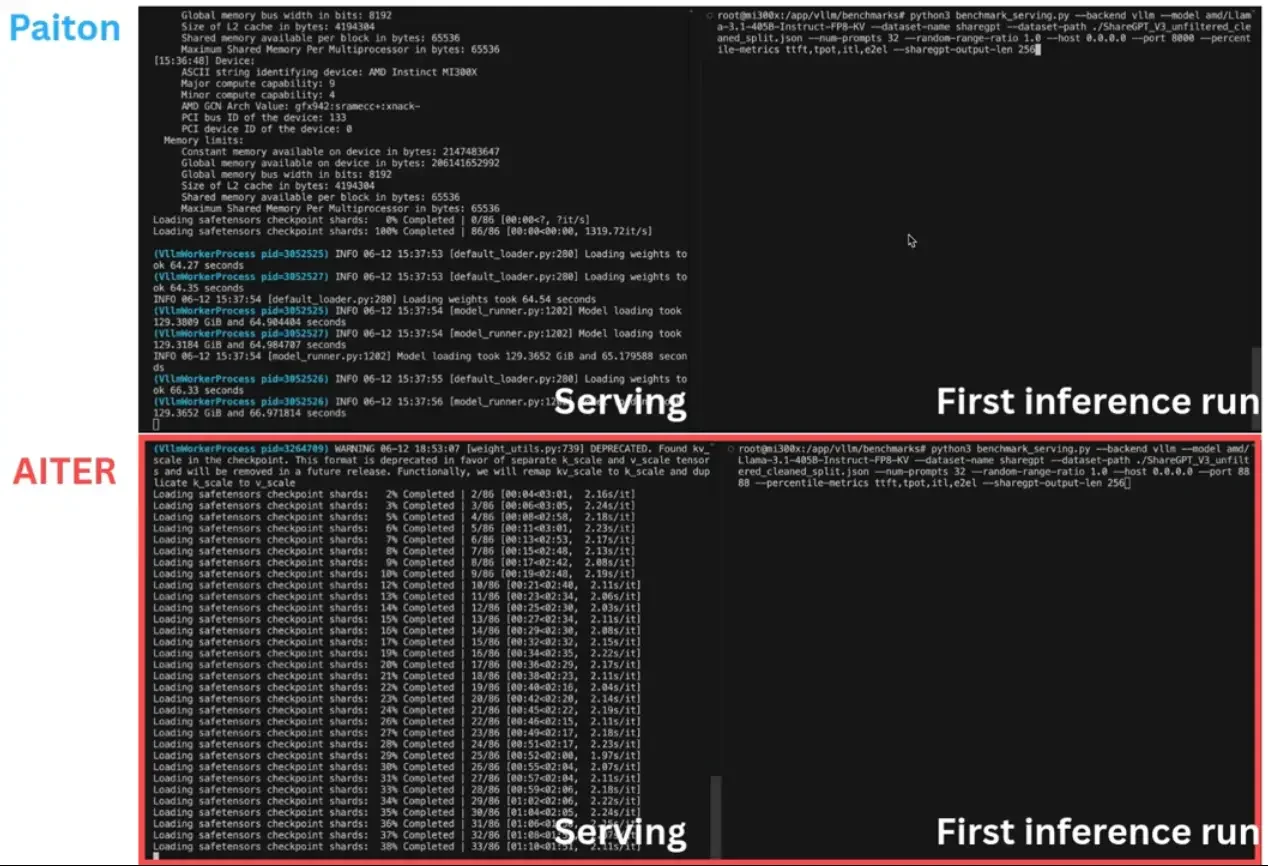
AMD MI300X Server + Paiton:
- System Tokens/sec: 7637.12 tokens/sec/GPU * 8 GPUs = 61,096.96 tokens/sec
- Tokens per hour: 61,096.96 tokens/sec * 3600 sec/hour = 219,949,056 tokens/hour
- Cost per hour: $260,564 / 26280 hours + 8.4kW * $0.10/kWh = $10.76
- Cost per 1M tokens: $10.76 / (219,949,056 / 1,000,000) = $0.049 per 1M tokens
Nvidia H200 Server:
- System Tokens/sec: 8192.08 tokens/sec/GPU * 8 GPUs = 65,536.64 tokens/sec
- Tokens per hour: 65,536.64 tokens/sec * 3600 sec/hour = 235,931,904 tokens/hour
- Cost per hour: $307,336 / 26280 hours + 7.8kW * $0.10/kWh = $12.48
- Cost per 1M tokens: $12.48 / (235,931,904 / 1,000,000) = $0.053 per 1M tokens
AMD RX 7900 XTX Workstation:
- System Tokens/sec: 1113.59 tokens/sec/GPU * 2 GPUs = 2227.18 tokens/sec
- Tokens per hour: 2227.18 tokens/sec * 3600 sec/hour = 8,018,153 tokens/hour
- Cost per hour: $3,500 / 26280 hours + 1.054kW * $0.10/kWh = $0.24
- Cost per 1M tokens: $0.24 / (8,018,153 / 1,000,000) = $0.030 per 1M tokens with a context length of 22048
Tenstorrent Loudbox:
- System Tokens/sec: 1314 tokens/sec/card * 4 cards = 5256 tokens/sec
- Tokens per hour: 5256 tokens/sec * 3600 sec/hour = 18,921,600 tokens/hour
- Cost per hour: $12,000 / 26280 hours + 1.9kW * $0.10/kWh = $0.65
- Cost per 1M tokens: $0.65 / (18,921,600 / 1,000,000) = $0.034 per 1M tokens
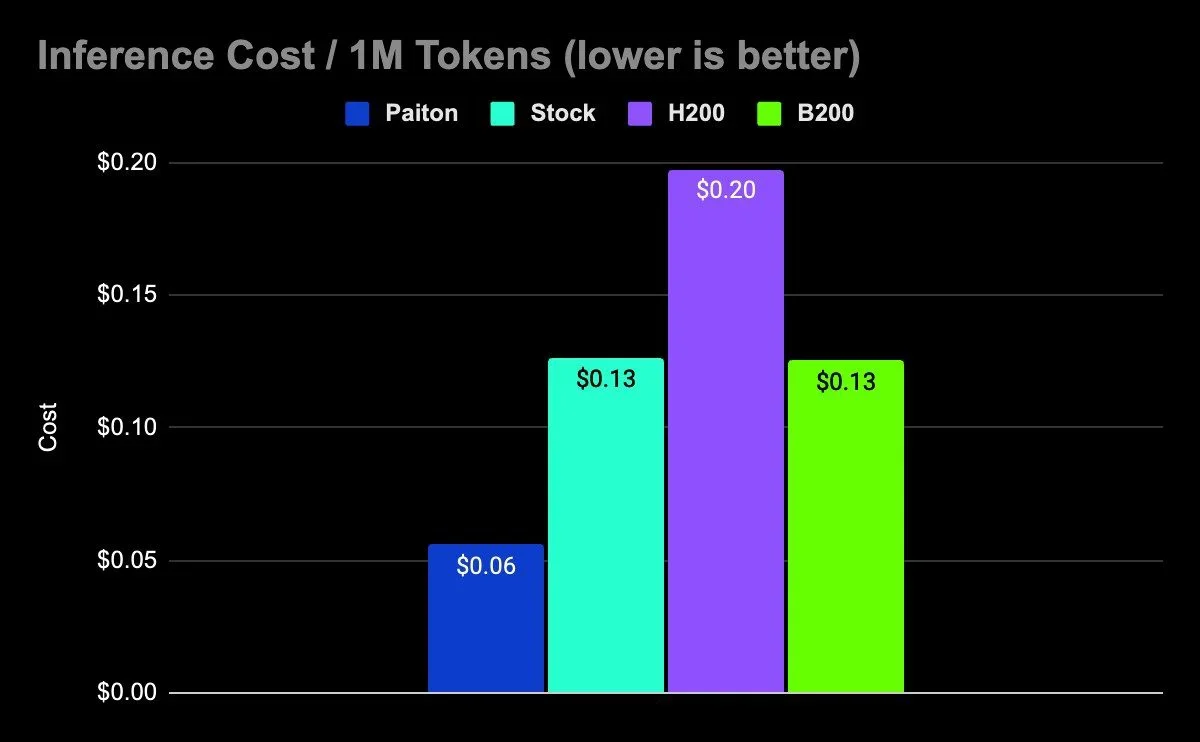
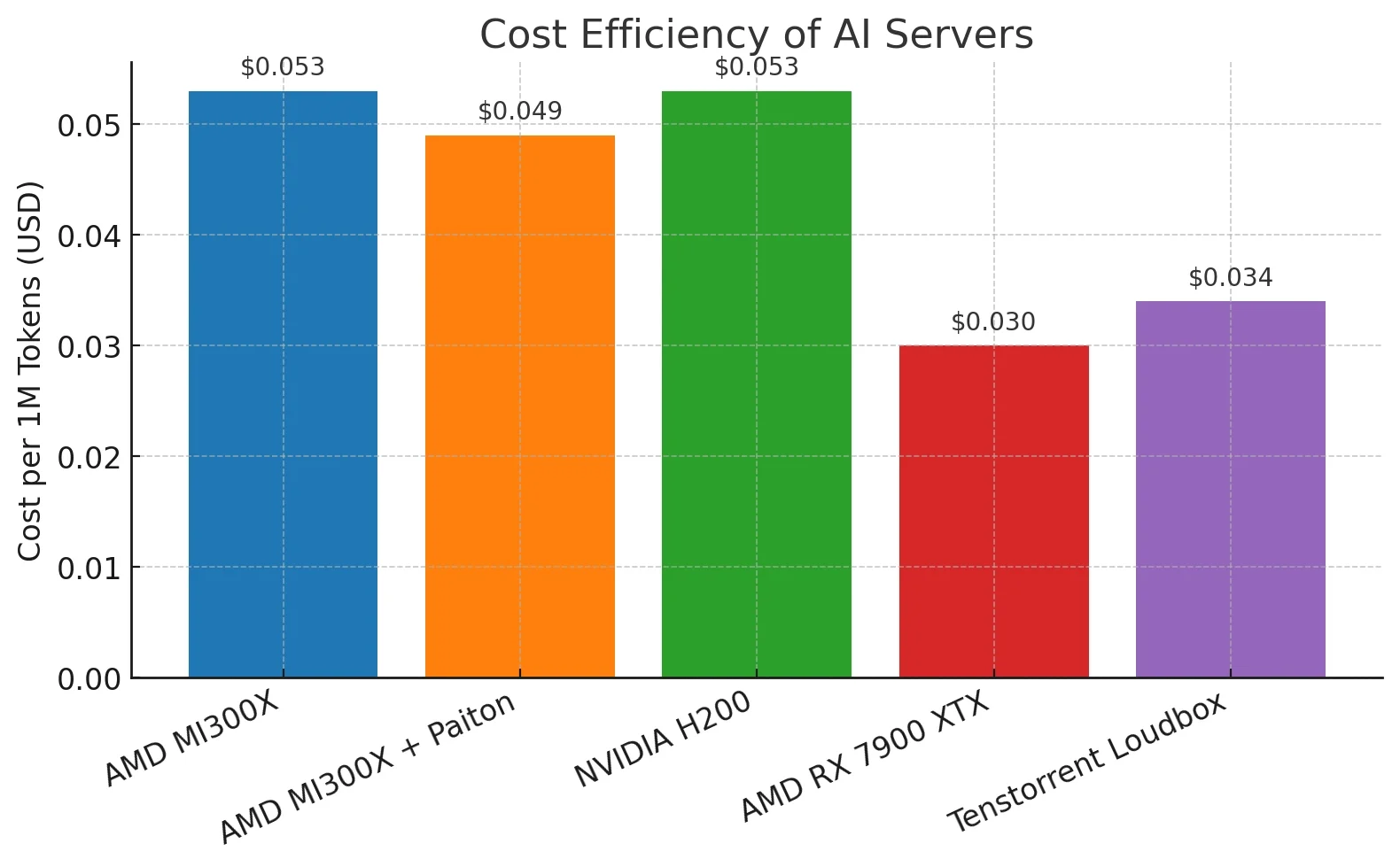
| Server | Cost per 1M Tokens |
| AMD MI300X | $0.053 |
| AMD MI300X + Paiton | $0.049 |
| NVIDIA H200 | $0.053 |
| AMD RX 7900 XTX | $0.030 (lower context length) |
| Tenstorrent Loudbox | $0.034 |
Observations
AMD MI300X: Competitive throughput with massive VRAM. Ideal for mid-to-large batch sizes and larger models like Llama 3-70B and beyond. Comparing a model like Llama3-8B was purely done due to the other cards not being able to load larger models on a single GPU, the MI300X should not be used for these use-cases unless GPU partitioning is done.
AMD MI300X + Paiton: Including the observations we’ve discussed above, Paiton achieved a 8.2% lower cost per million tokens compared to the standard MI300X setup, demonstrating improved cost-efficiency from software optimizations. The Paiton Framework is continuously improving, and as development progresses, this cost will continue to decrease over time.
NVIDIA H200: Industry-leading speed, similar to the AMD MI300X, and a mature CUDA software stack. Ease-of-use is definitely the case with Nvidia.
RX 7900 XTX: A cost-effective choice for individual developers. Not ideal for larger workloads due to VRAM limitations and the annoying context-length limitation, but great for light inferencing and development. Useful for AI/ML workloads and any other general GPU related workload.
Tenstorrent n300s: Innovative RISC-V architecture tailored for ML workloads. Emerging support in inference frameworks like vLLM, but the ecosystem is still growing. The cost per 1M tokens is competitive for smaller models, if the model is supported.
Final Thoughts
Choosing the right server hinges on your use case:
- Startups or researcher: RX 7900 XTX workstation or Tenstorrent Loudbox for low-cost experimentation and inference (just make sure the model you want to use is supported by Tenstorrent).
- Enterprises: MI300X and H200 balance performance and efficiency well, however, the MI300X GPU does provide significantly larger VRAM at a lower cost.
Given the surprisingly competitive cost-efficiency of the RX 7900 XTX in this analysis, we’re excited to announce that RDNA support for Paiton is currently in development to further unlock the potential of these GPUs.
In a fast-evolving AI hardware landscape, pairing the right accelerator with optimized inference frameworks like vLLM ensures you’re making the most of your infrastructure.