Paiton FP8 Beats NVIDIA’s H200 on AMD’s MI300X
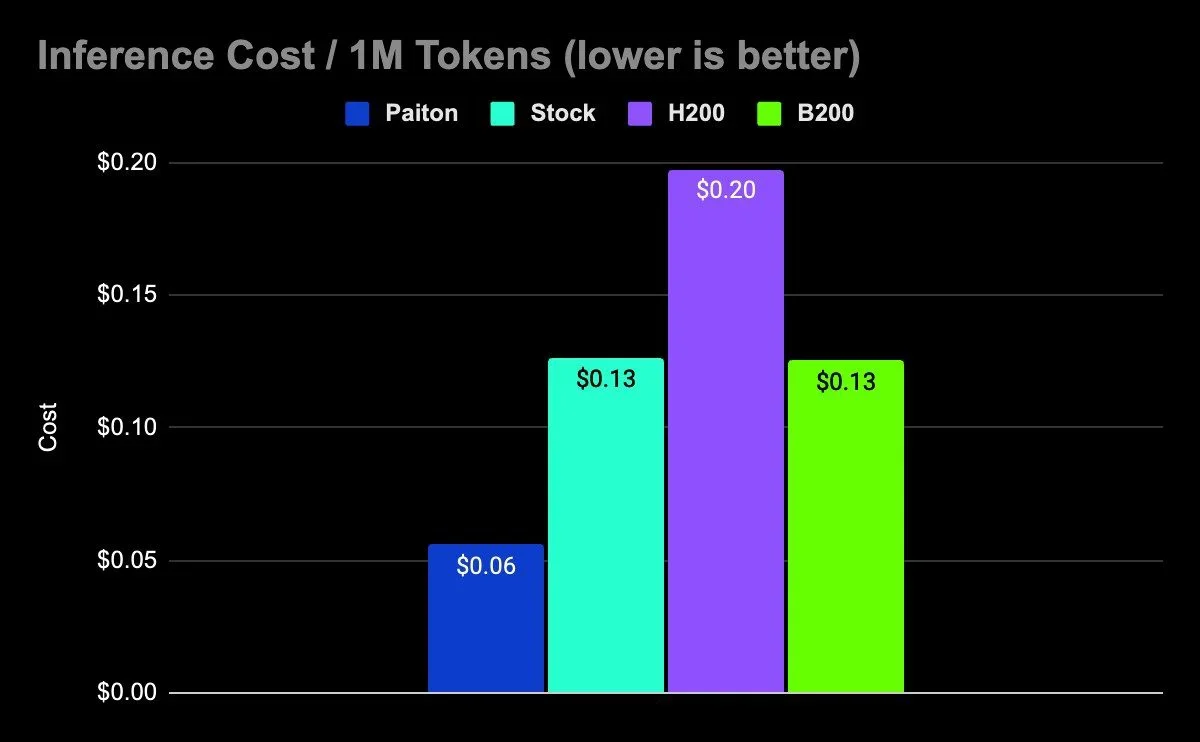
The world of AI is moving at an unprecedented pace, and efficient inference is key to deploying powerful models in real-world applications. At Eliovp, we’ve consistently pushed the boundaries of AI performance, as highlighted in our previous blogs showcasing significant inference speedups when benchmarking with fp16/bf16. Now, we’re thrilled to announce a further significant leap forward: Paiton now achieves superior inference performance on AMD MI300X GPUs with FP8, outperforming NVIDIA’s H200. While both AMD and NVIDIA support FP8, our meticulously optimized kernels deliver these breakthrough results.
For too long, the narrative around AI hardware has been dominated by a single player. However, AMD’s MI300 series is a game-changer, offering incredible compute power. The challenge, as always, lies in extracting every ounce of that power. That’s where Paiton comes in.
Our core mission at Paiton is to optimize existing AI models by fine-tuning the kernels used for inference, with a specific focus on AMD architectures. We dive deep into the underlying operations, rewriting, fusing, and refining them to perfectly align with the unique strengths of AMD’s hardware. The result? Dramatically faster inference speeds and more efficient resource utilization.
Testbed & Methodology
To ensure transparency and reproducibility, here’s our benchmarking setup:
As always, we made sure to use the best possible setup to keep things fair.
- Inference Library: vLLM v0.9.0 + amd/Llama-3.1-70B-Instruct-FP8-KV
- Hardware: AMD MI300X (192 GB HBM3) vs. NVIDIA H200 (141GB HBM3e)
- Software Stack: ROCm 6.3.1 (we know we can get even better results when upgrading to 6.4) on Ubuntu 22.04; CUDA 12.x on Ubuntu 22.04
- Measurements: Averaged over 10 inferences, capturing both cold-start and steady-state Time to First Token (TTFT) and end-to-end latency (API call → final token).
- Batch Sizes: 1–128 to reflect interactive AI loads (1–64) vs. batch-processing extremes (128).
The FP8 Advantage: The Era of Efficiency
The introduction of FP8 (8-bit floating point) precision has been a monumental step towards more efficient AI inference for the industry as a whole. By reducing the memory footprint and computational intensity, FP8 allows for larger models to be deployed or existing models to run at significantly higher throughputs while utilizing less memory. While FP8 support is available across modern AI hardware platforms from both AMD and NVIDIA, harnessing its full potential requires highly optimized software implementations.
We’ve been working tirelessly to integrate and optimize our kernels for FP8 on AMD. We’re incredibly proud to announce that our recent benchmarks demonstrate a clear victory for AMD MI300X equipped with Paiton’s optimized kernels.
Paiton on AMD MI300X: Setting a New Standard
Our internal testing shows that with Paiton’s optimized kernels, the AMD MI300X GPU achieves demonstrably better results compared to the NVIDIA H200 GPU when running the amd/Llama-3.1-70B-Instruct-FP8-KV model for inference in FP8 precision.
Here are the benchmark results comparing NVIDIA H200 and AMD MI300X performance with Paiton’s optimized kernels:
| Batch | H200 (Req/s) | MI300X + Paiton (Req/s) | H200 (Tok/s) | MI300X + Paiton (Tok/s) | H200 E2E (ms) | MI300X E2E (ms) | H200 TTFT (ms) | MI300X TTFT (ms) | Overall Winner |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.16 | 0.17 | 39.9 | 43.4 | 640.7 | 589.5 | 136.3 | 138.6 | Paiton |
| 2 | 0.31 | 0.34 | 78.5 | 87.0 | 518.5 | 477.7 | 133.6 | 122.4 | Paiton |
| 4 | 0.60 | 0.67 | 129.6 | 172.0 | 562.2 | 441.6 | 134.3 | 132.6 | Paiton |
| 8 | 1.18 | 1.31 | 225.0 | 252.1 | 587.6 | 493.3 | 269.9 | 280.9 | Paiton |
| 16 | 2.21 | 2.45 | 343.1 | 470.1 | 560.6 | 502.5 | 461.3 | 513.8 | Paiton |
| 32 | 3.93 | 4.07 | 591.8 | 814.5 | 659.1 | 640.6 | 1188.7 | 1187.5 | Paiton |
| 64 | 6.64 | 6.24 | 1297.4 | 1179.7 | 789.3 | 812.2 | 2362.3 | 1880.3 | Draw |
| 128 | 9.75 | 9.01 | 1821.9 | 1655.8 | 607.7 | 635.5 | 3633.3 | 3502.0 | H200 |
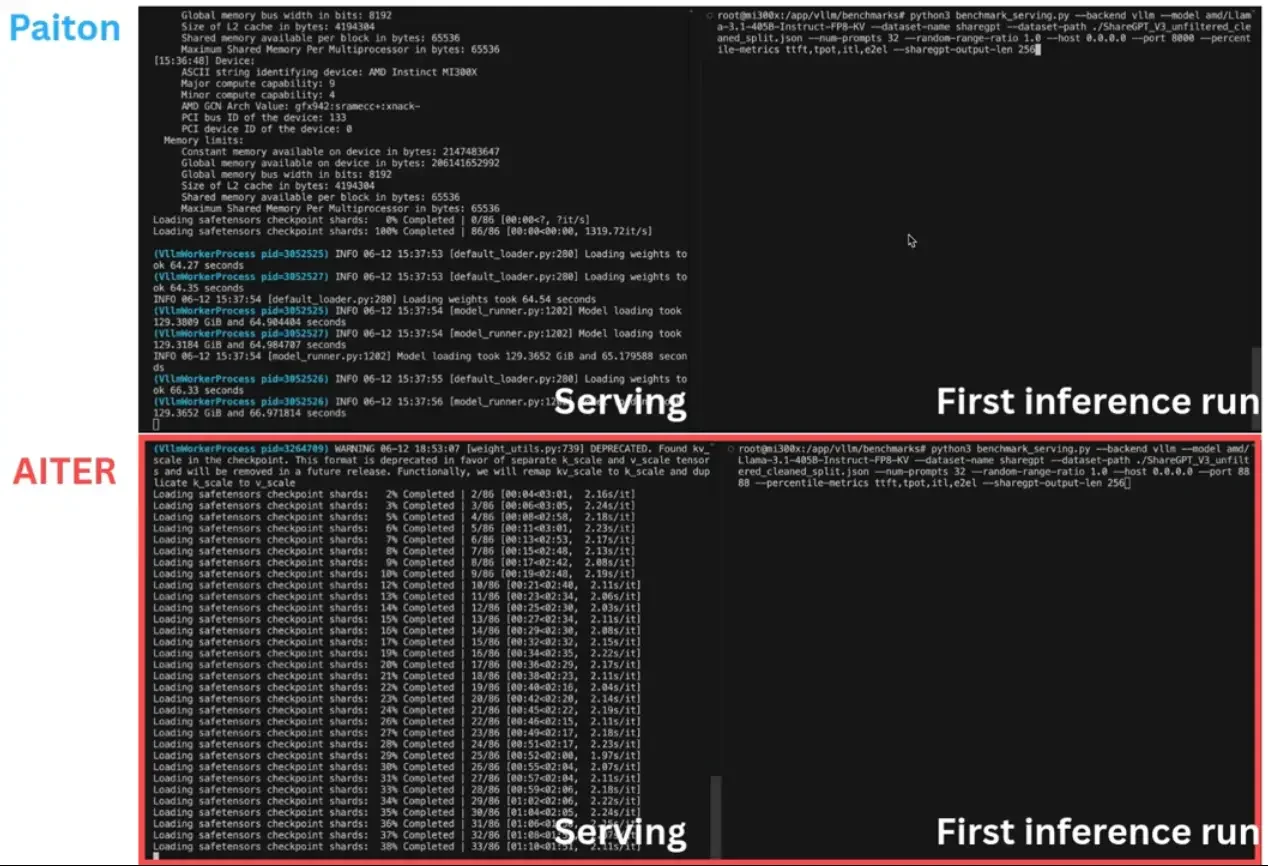
Note: In preliminary tests, Paiton’s FP8 kernels also outperformed AMD’s own Aiter engine on MI300X.
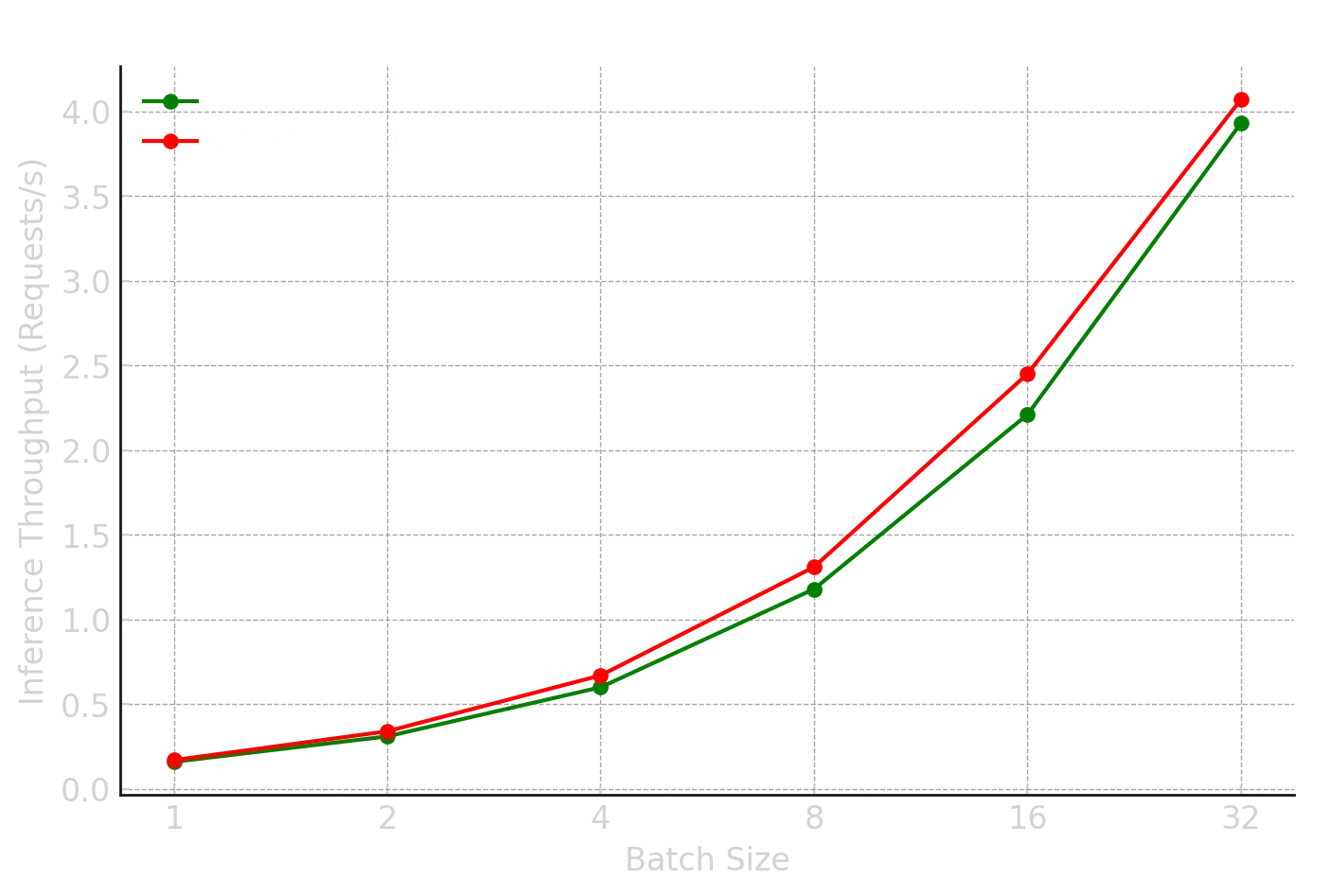
The qualitative results are undeniable: Paiton enables the AMD MI300X to process Llama-3.1-70B-Instruct-FP8-KV queries with higher throughput and lower latency than its NVIDIA counterpart across small to mid-range batch sizes, and often achieves better Time to First Token (TTFT). This is a direct testament to the power of targeted kernel optimization. While NVIDIA H200 shows strong performance at the highest batch sizes, our focus on optimizing for the most common real-world scenarios (smaller, more frequent requests, typical of interactive AI applications) demonstrates Paiton’s significant and impactful advantage in practical deployments. This means faster responses for end-users and more efficient utilization of your AMD hardware in common operational profiles.
Why This Matters for You
- Unleash AMD’s True Potential: Investing in cutting-edge hardware like AMD MI300X GPUs should mean unlocking their full capabilities, not leaving performance on the table due to generic software. Paiton ensures you’re extracting every possible compute cycle, allowing your AMD infrastructure to reach its maximum potential for AI inference workloads. Our fine-tuned kernels mean your GPUs are working at peak efficiency, minimizing idle time and maximizing useful computation.
- Cost-Effective AI Deployment: Higher inference efficiency directly translates into tangible cost savings. When your models run faster and more efficiently, you can process more requests, or complete existing workloads in less time. This directly impacts your operational expenses, whether you’re managing an on-premise data center or utilizing cloud-based GPU instances. Over time, these optimizations can lead to substantial reductions in your total cost of ownership for AI infrastructure.
- Future-Proof Your Deployments: The landscape of AI models is constantly evolving, with a clear trend towards larger, more complex architectures and the adoption of lower precision formats like FP8. As these models grow and their computational demands intensify, highly optimized inference solutions will become not just beneficial, but absolutely critical for maintaining performance and scalability. Paiton’s continuous development ensures your AI deployments remain at the forefront, ready to handle the next generation of models and precision requirements with confidence.
- Broader Hardware Choice: Our work with Paiton empowers developers and organizations to confidently choose AMD for their demanding AI inference needs. By demonstrating superior performance on AMD MI210, MI250X, MI300X, MI325X, MI355X, we’re fostering a more competitive and innovative hardware ecosystem, giving you more flexibility and options in designing your AI infrastructure. This competition drives innovation across the industry, ultimately benefiting all users.
The era of one-size-fits-all AI optimization is rapidly drawing to a close. Paiton is at the forefront, leading the charge in delivering specialized, high-performance solutions meticulously crafted for AMD GPUs. With our latest enhancements, including the breakthrough FP8 optimizations, we’re not just optimizing; we’re actively redefining what’s possible for AI inference on AMD hardware.
Stay tuned for more in-depth technical breakdowns and further benchmark releases as we continue to push the boundaries of AI performance, and during these FP8 benchmarks we uncovered additional optimization techniques that we’ll showcase in upcoming deep-dive posts! We’ll soon be sharing exciting results on Tensor Parallelism (TP), where Paiton continues to demonstrate superior performance and scalability, even surpassing AMD’s own AITER engine in our internal tests. If you’re running AI models on AMD hardware, it’s time to experience the Paiton difference and see how our kernel optimizations can elevate your AI inference capabilities.
If you’re running AI models on AMD hardware, it’s time to experience the Paiton difference and see how our kernel optimizations can elevate your AI inference capabilities.
Reach out for a demo and elevate your AI inference performance today!
– The Paiton Team –