Power Meets Precision: High-Density Modular Data Center for NVIDIA NVL Deployments (1–2 MW)
Purpose-Built High-Density Infrastructure for Blackwell-Class AI Workloads
At Eliovp, we’re engineering a new class of AI infrastructure. Our advanced modular platform is built to also support NVIDIA’s cutting-edge NVL architecture, from the efficient NVL4 to the ultra-scale NVL72, enabling deployments that range from distributed edge inference to full-stack model training at hyperscale.
Designed to meet the increasing thermal and power demands of next-generation GPU workloads, Eliovp’s modular systems deliver 1–2 MW of compute power per unit in a compact, prefabricated footprint. These solutions are scalable, efficient, and deployment-ready in under 6 months.
Whether you’re deploying 1 or 2 megawatts of GPU compute, our modular architecture delivers the scalability, efficiency, and resilience your AI workloads demand, all within a 12–17m footprint (depending on level of redundancy/maintainability).
Built for NVIDIA NVL: Peak Performance in a Compact Footprint
The NVIDIA NVL family is engineered for next-gen AI: from training massive language models like GPT-4 to powering real-time inference in edge environments. Here’s a breakdown of the NVL configurations our modular centers are optimized for:
NVIDIA NVL4 (Coming Soon)
- Configuration: 4× Blackwell GPUs (B200-class), 2× Grace CPUs via NVLink
- Power Draw: ~6.6 kW
- Use Case: Supercomputing, scientific simulations, distributed inference
- Key Benefits:
- Edge-ready with a smaller power footprint
- Low-latency NVLink GPU-to-GPU
- Ideal for micro-modular deployments
- NVSwitch + NVLink, BlueField connectivity
NVIDIA NVL72
- Configuration: 144 Blackwell GPUs, 72 Hopper CPUs
- Power Draw: ~120 kW per rack
- Use Case: Full-scale LLM training (GPT-4, Llama 3/4)
- Key Benefits:
- Designed for massive parallel compute
- Ultra-fast interconnects for model training at scale
- NVSwitch + NVLink, BlueField connectivity
Technical Architecture Overview
Our modular solution isn’t just a shipping container with racks. It’s a complete data ecosystem, pre-engineered, prefabricated, and globally deployable.
| Parameter | Value / Specification |
| IT Capacity | 6-10 high-density DLC racks per module (2-4 Additional racks for storage and network) |
| Rack-Level Power Envelope | Nominal: 80 kW, Peak: 150 kW per rack |
| Total Module IT Load | 1.0 MW operational average, scalable to 1.1–2.2 MW per unit |
| Cooling Design | RDHx/DLC hybrid, N+1 redundant Drycoolers/Chillers (Glycol PG25) |
| Power Topology | N+1 UPS per POD, integrated (expandable to 2N) |
| Redundancy Philosophy | Full component-level redundancy (RDHx, chillers, pumps) |
| Glycol Solution | PG25 (≤40%) – anti-freeze, anti-biofilm, low-maintenance |
| Deployment Time | 18–24 weeks (spec to install) |
| Compliance | TIER III-ready |
| Rack Density | Up to 130 kW/rack Nominal load. |
Each Eliovp unit utilizes a vendor-agnostic, standards-compliant design paradigm, allowing rapid integration of NVIDIA Blackwell-based NVL systems while retaining flexibility for AMD MI300 or future hybrid AI compute environments.
Rack and Cooling System Integration
Eliovp’s modular architecture integrates high-density direct liquid to chip cooling (DLC) loops in combination with Rear Door Heat Exchangers (RDHx), enabling precise thermal regulation, reduced loop complexity, and scalable coolant delivery across high-power compute racks.
Key Cooling Specifications
Chiller Configuration
N+1 redundant drycoolers or chiller sets with integrated glycol buffer vessels and Grundfos variable-speed pump sets, ensuring stable thermal delivery and hydraulic balancing under dynamic compute loads.
Direct-Liquid-to-Chip Cooling (DLC)
High-efficiency cold plate loops directly interfaced with GPU/CPU die surfaces via the CDU loop. Designed for thermal loads exceeding 100 kW/rack, with low ∆T and minimal thermal resistance.
Rear Door Heat Exchanger (RDHx) Strategy
Rack-mounted liquid-to-air RDHx units extract residual heat (5% for the NVL4 and around 18% for de NVL 72) post-DLC loop. Each unit is designed with passive and active failover capability to maintain airflow and thermal extraction in the event of a localized failure.
Coolant Composition
Closed-loop circulation of PG25 glycol solution (up to 40%) provides freeze protection, microbial resistance, and minimal fouling across the thermal exchange surfaces.
Optional Adiabatic Dry Coolers
For deployments in favorable climates, traditional mechanical chillers can be partially or fully replaced with adiabatic dry cooling arrays, significantly reducing PUE and OPEX during shoulder seasons.
Built-in Advantages
- Liquid cooling + RDHx for optimal thermals
- Side-by-side container format for site flexibility
- Integrated fire suppression, telemetry, and access control
Scalable, Redundant Power Distribution
Eliovp’s power infrastructure is tailored for high-density GPU deployments. Each 1000 kW POD integrates dual power feeds (A and B), physically housed within a single electrical container featuring an internal partition for fault isolation and maintenance access. This modularized format supports fast deployment, high reliability, and future scalability to 2.2 MW through busbar augmentation and utility-side expansion.
Integrated Electrical Container (1MW Dual Feed POD)
UPS Architecture
Redundant 2× modular UPS blocks in decentralized parallel architecture (DPA), mounted within a 40ft container. Both A and B feeds share the enclosure, separated by a central fire-rated wall for physical and electrical segregation.
Busbar Distribution
IT load and cooling infrastructure are powered via segmented 1600 A copper busbars, with integrated tap-off units at 250 A and 125 A for sub-distribution.
Breaker Configuration (1000 kW)
| Function | Rating | Configuration |
| Transformer Input | 2000 A | Dual feed |
| Generator Breaker | 2000 A | A+B redundancy |
| UPS Output Breaker | 1600 A | Integrated modular UPS x2 |
| Maintenance Bypass | 2000 A | Fully rated bypass capability |
| IT Load Distribution | 1600 A | +1×250 A, +1×125 A |
| Cooling Distribution | 400 A | +1×250 A, +1×125 A |
| Total Switchgear Width | 5.4 m | Including full-length LV panels |
Fire Safety Integration
Each container includes full VESDA smoke detection, argon gas suppression, and local emergency shutoff interfaces.
Emergency Power Generation (NSA Containerized System)
To ensure grid-agnostic, uninterrupted operation, each 1 MW POD is backed by 2N containerized gensets systems that are prime rated to the maximum load of the IT and cooling equipment with the following specs:
- Prime Power: 1224 kVA / 979 kW
- Standby Power: 1320 kVA (continuously running capacity)
- Genset: Baudouin 16M33G1320/5 engine + Xingnuo XN6F alternator
- Container: 40ft high-cube with:
- Integrated sound dampening up to 80 dB(A) @1m
- Internal fire detection and access security
- 1500-liter integrated fuel tank (48 hrs supply)
- Dry Weight: 11,183 kg
Scalability Path
- Base Configuration: 1.0 MW per POD (dual A+B feed)
- Scalable To: 2.2 MW per module via:
- Busbar capacity upgrade
- Additional chiller/UPS capacity
- Genset pairing with 1640 kW (2×2000 kVA) NSA modules
All power delivery components are fully compliant with IEC 61439, and configured for integration into Tier III/IV-aligned operational topologies (including 2N-ready configurations for mission-critical deployments).
Why TIER III Matters: Enterprise-Grade Uptime
We’ve designed our system to meet Uptime Institute’s TIER III standards, making it ideal for mission-critical workloads where every second counts.
Concurrent Maintainability
Perform maintenance without downtime. Power, cooling, and connectivity systems are all independently serviceable.
Redundant Paths (N+1)
Every critical system has at least one backup, ensuring resilience and availability.
Uptime SLA: 99.982%
That’s less than 1.6 hours of downtime per year. Perfect for AI-powered enterprises where reliability is everything.
Fire Safety, Maintenance, and Environmental Controls
- Fire Detection/Suppression: Dual-gas Argonite system with continuous VESDA laser detection
- Environmental Monitoring: Leak detection, pressure sensors, temperature/flow telemetry
- Maintenance Schedule:
- UPS checks: Annually
- Chillers/filters: Biannually to quarterly
- Transformer/Generator: 3-year cycle with monthly ops check
- Integration Partners: Maintenance contracts available with our partners
Global-Ready, AI-Optimized
Whether you’re scaling up a cloud platform, building a national AI hub, or deploying mission-critical AI in the field: Eliovp delivers fast, scalable infrastructure wherever you need it.
From regional clusters to hyperscale-ready edge deployments, our modular systems are built for speed, flexibility, and global compliance.
Eliovp Lite: Cost-Effective Solution for Non-Critical Workloads
Understanding that not every AI deployment requires enterprise-grade redundancy, we’ve developed A Lite setup, a streamlined solution with a significantly smaller footprint and lower cost structure while maintaining compatibility with NVIDIA NVL architectures.
Eliovp Lite Specifications
| Parameter | Value / Specification |
| ITE Capacity | 10-14 racks per module |
| Rack-Level Power | Up to 120 kW per rack |
| Total Module IT Load | 500-1.000 kW per unit |
| Cooling Design | DLC/RDHx Hybrid |
| Power Topology | Single-path power distribution (non-redundant) |
| Deployment Time | 16-18 weeks |
| Footprint | 8m × 17m compact configuration |
Ideal for:
- Academic and research environments
- Development and testing clusters
- Small to medium AI startups
- Edge computing applications
Eliovp Lite eliminates costly redundancies while maintaining thermal efficiency for NVL hardware. This solution offers a perfect balance for organizations with:
- Budget constraints
- Space limitations
- Workloads that can tolerate occasional maintenance windows
By removing dual power paths, redundant cooling systems, and enterprise-grade backup generators, we’re able to reduce initial capital expenditure by up to 40% while still providing a professional-grade environment for AI computation. The streamlined design also reduces ongoing operational costs through simplified maintenance procedures and reduced power overhead.
Versatile Hardware Support
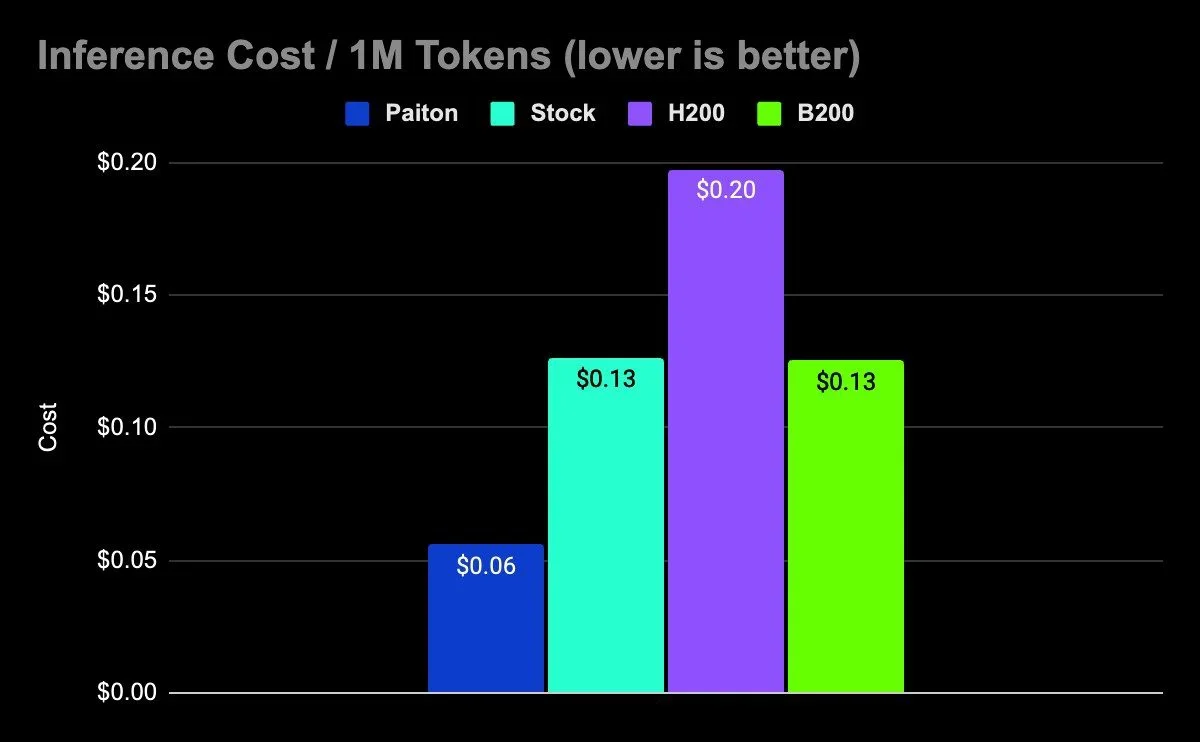
And it’s not just NVIDIA, our modular AI data centers are also designed to support AMD GPUs, making them an excellent choice for inference-focused deployments where cost-efficiency and performance go hand-in-hand.
Conclusion: Eliovp = NVL-Grade AI Infrastructure
Our modular AI architecture is uniquely equipped to deploy the most power- and cooling-intensive NVL configurations, NVL72-scale LLM training clusters or NVL4 edge AI inference units with uncompromising uptime, thermal stability, and operational flexibility.
We engineer infrastructure, not containers.
Ready to get started? Get in touch to explore which design and configuration best fits your needs and secure your place in this transformative AI era.