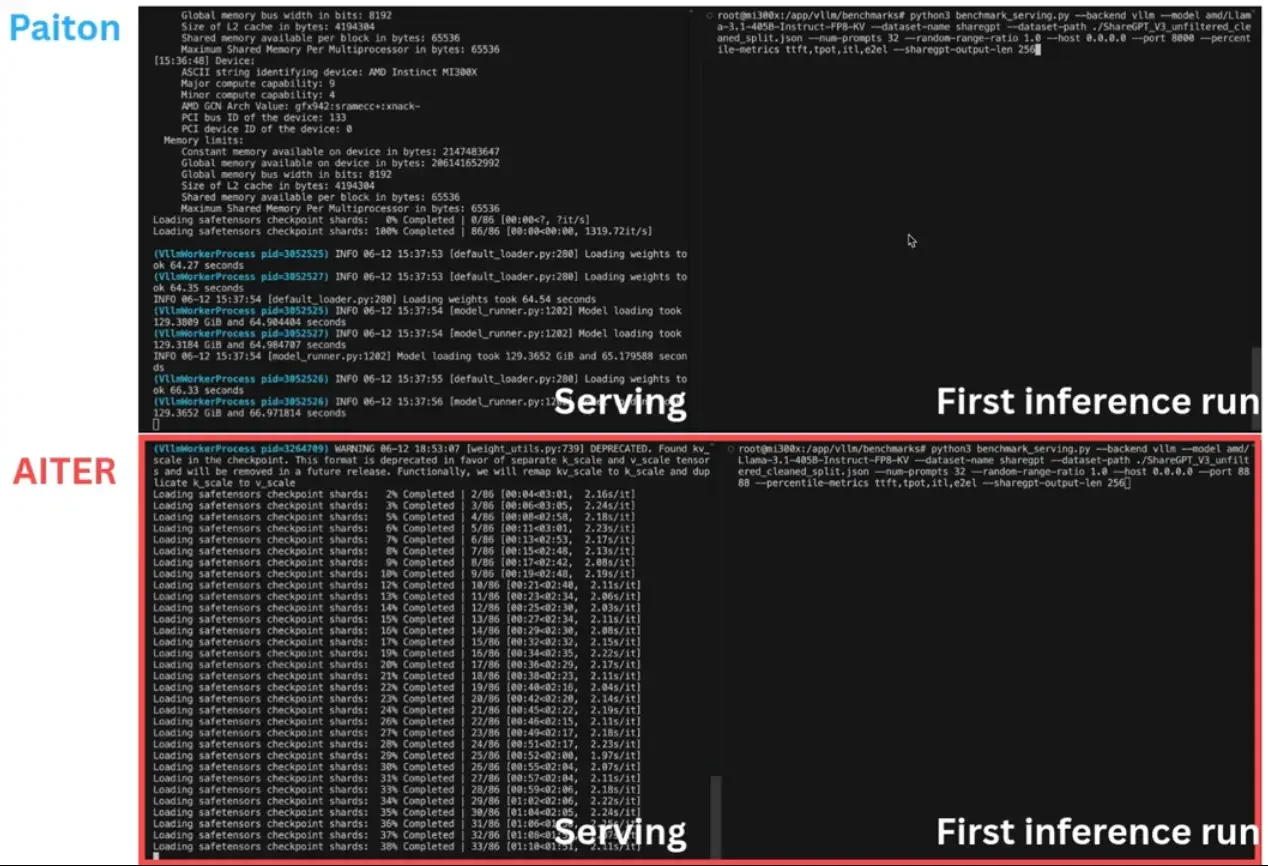
The Rise of Open-Source AI Model Optimization
In the rapidly evolving landscape of artificial intelligence (AI), open-source solutions are emerging as pivotal drivers of innovation and performance enhancement. These community-driven platforms democratize access to cutting-edge technologies, fostering collaboration and accelerating advancements in AI model optimization.
The Open-Source Revolution in AI
Open-source AI models have transformed the development and deployment of machine learning applications. By providing transparent, modifiable, and freely accessible codebases, these models empower developers and organizations to tailor AI solutions to their specific needs. This flexibility not only reduces dependency on proprietary systems but also encourages a culture of shared knowledge and continuous improvement.
One notable example is DeepSeek-R1, an open-source model released by the Chinese AI company DeepSeek. Despite being developed with significantly fewer resources than its counterparts, DeepSeek-R1 has demonstrated performance comparable to industry leaders like OpenAI on various benchmarks. This achievement exemplifies the power of “frugal innovation,” where resource constraints drive creative problem-solving and efficient model optimization.
More recently, Anthropic’s Claude 3 family and Meta’s Llama 3 models have demonstrated that open and partially open models can achieve performance rivaling or exceeding closed-source solutions, challenging the notion that AI development requires enormous proprietary resources.
Paiton: Pioneering AI Optimization Software
In this dynamic environment, our Paiton tool stands out as a leading AI model optimization software. Designed to enhance the performance of AI models, Paiton has consistently delivered improvements ranging from 15% to 30% on AMD Instinct Accelerators such as the MI3** series, often surpassing the performance of equivalent Nvidia hardware. By leveraging advanced optimization techniques, Paiton enables organizations to maximize the efficiency and effectiveness of their AI deployments.
Groundbreaking Hardware Advancements from GTC 2025
The recent NVIDIA GTC 2025 conference has unveiled several game-changing developments in AI hardware optimization that are reshaping the industry landscape:
NVIDIA’s Revolutionary Rubin AI Chip
NVIDIA has just unveiled its next-generation AI accelerator, the Rubin chip, at GTC 2025. Building on the success of the Blackwell architecture, Rubin represents a quantum leap in AI processing capabilities. According to NVIDIA CEO Jensen Huang, the Rubin chip delivers up to 3x better performance-per-watt compared to the previous generation B200 Blackwell GPU, with specialized circuitry for accelerating transformer architectures and multi-modal AI workloads.
The Rubin platform introduces a new memory architecture that reduces data movement bottlenecks by 60%, addressing one of the most significant efficiency constraints in current AI systems. This advancement is particularly relevant for optimization-focused solutions like Paiton, as it opens new avenues for hardware-aware model tuning that can exploit these architectural innovations.
ARM-Based AI Acceleration
Another significant announcement from GTC 2025 was NVIDIA’s expanded partnership with ARM to develop specialized AI cores for edge devices. This collaboration aims to bring server-class AI capabilities to power-constrained environments, enabling efficient inference for complex models on smartphones, vehicles, and IoT devices. The new reference designs demonstrate a 4x improvement in energy efficiency compared to previous generations, making advanced AI applications viable in scenarios where power and thermal constraints were previously prohibitive.
Emerging Trends in AI Model Optimization
The field of AI model optimization is witnessing several key trends that are shaping its future trajectory:
- Tencent’s T1 Reasoning Model
In a major development for open-source AI, Chinese tech giant Tencent has recently released its T1 reasoning model, specifically designed to excel at complex reasoning tasks. According to Tencent’s research team, the T1 model introduces a novel architecture that separates the reasoning process from knowledge representation, allowing for more efficient parameter utilization.
Initial benchmarks show that T1 outperforms Meta’s Llama models on Chinese language tasks by a significant margin, while requiring 35% less computational resources for inference. The model also demonstrates outstanding performance on cross-lingual reasoning benchmarks, indicating that its architectural innovations translate well across different languages and domains.
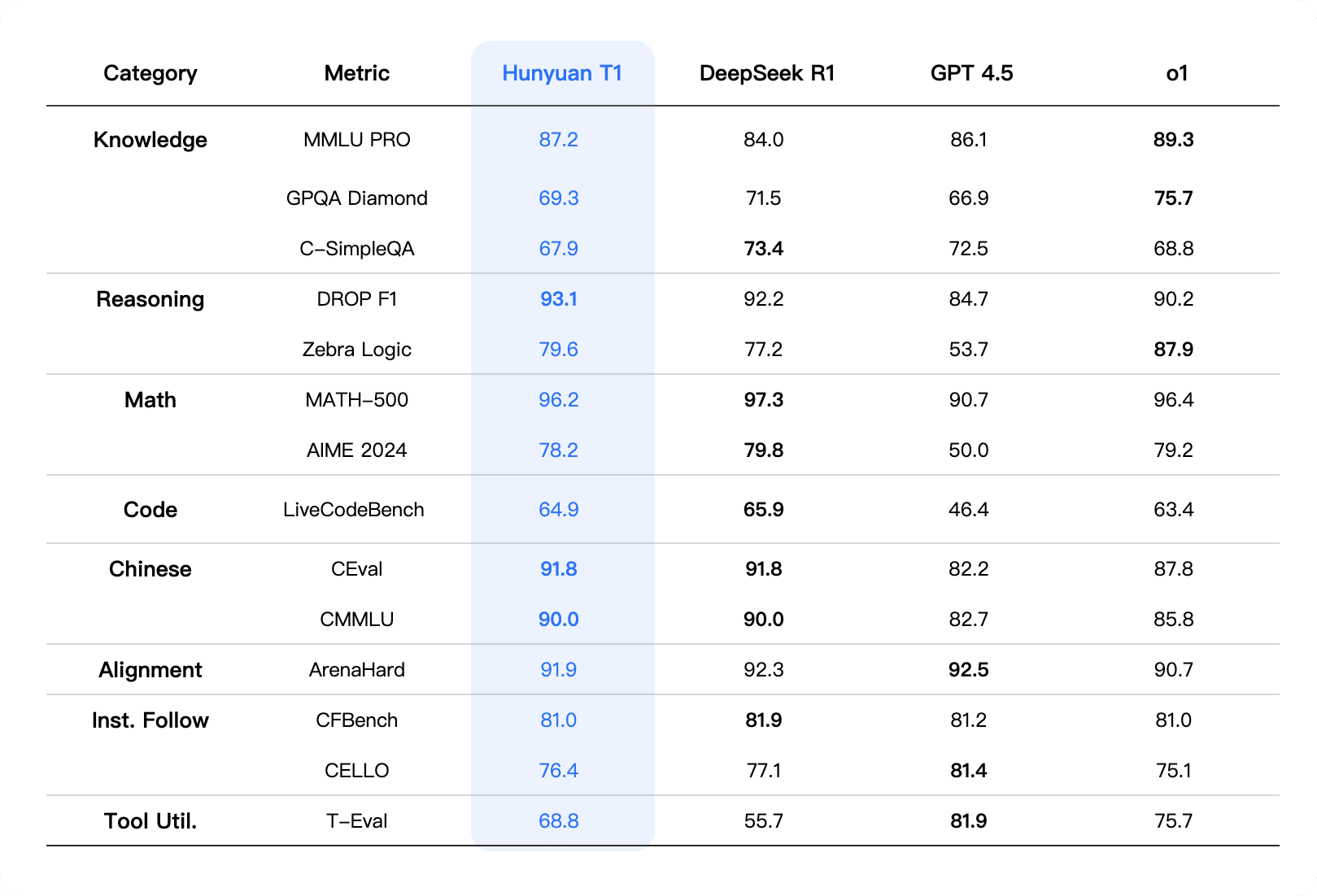
Tencent has opened access to the model weights and optimization techniques through their GitHub repository, providing valuable resources for the open-source community to build upon. This release represents a significant contribution to democratizing advanced AI capabilities and shows how optimization-focused approaches can lead to models that are both more capable and more efficient.
- Advanced Quantization Techniques
Recent breakthroughs in quantization are revolutionizing model optimization. Google’s Gemma and Mistral AI’s Mistral models have demonstrated that aggressive quantization (to 2, 3, or 4 bits) can maintain impressive performance while dramatically reducing memory requirements. The GPTQ and AWQ quantization techniques have become industry standards, with research from MIT and Stanford showing memory footprint reductions of up to 55% while improving inference speed by 2-4x.
- Sparse Mixture of Experts (MoE) Architecture
The MoE architecture, exemplified by models like Mixtral 8x7B and Google’s Gemini, has emerged as a powerful approach to scaling model capabilities without proportionally increasing computational demands. By selectively activating only relevant “expert” sub-networks for each input, MoE models can achieve performance comparable to models several times their size. Recent benchmarks show MoE models delivering 30-40% better performance-per-parameter than dense architectures.
- Agentic AI Systems
Developing AI agents capable of autonomous decision-making and learning is becoming increasingly prevalent. These systems can adapt to dynamic environments and perform complex tasks with minimal human intervention. Microsoft’s AutoGen and the open-source LangChain framework have become standard tools for building these agent systems, with recent enhancements in reasoning capabilities through ReAct and Tree-of-Thought prompting techniques.
- Custom Silicon and Hardware Optimization
The design of specialized hardware, such as custom silicon chips, is enhancing the performance and efficiency of AI models. This trend includes the development of processors tailored for specific AI workloads, reducing power consumption and improving processing speeds. Beyond Nvidia’s dominance, companies like AMD with their MI300X accelerators and startups like Cerebras and Groq are pushing the boundaries of AI-specific hardware, with the latter demonstrating unprecedented token generation speeds of over 1,000 tokens per second on large language models.
- Multimodal AI Integration
Integrating multiple data modalities—such as text, images, and audio—into a single model allows for more comprehensive and context-aware AI applications. This trend is driving advancements in areas like natural language processing and computer vision. Recent multimodal models like Claude 3 Opus, GPT-4 Omni, and Gemini Ultra have demonstrated remarkable capabilities in understanding and generating content across different modalities, with the latest benchmarks showing near-human performance on complex reasoning tasks combining visual and textual information.
- Retrieval-Augmented Generation (RAG)
RAG has emerged as a crucial technique for enhancing model accuracy and reducing hallucinations by retrieving factual information from external knowledge bases during generation. Open-source frameworks like LlamaIndex and LangChain have made implementing sophisticated RAG pipelines accessible to developers of all skill levels. Recent innovations include hybrid retrieval methods that combine dense and sparse embeddings, reducing retrieval latency by up to 40% while improving relevance.
- Edge AI Optimization
Deploying AI algorithms directly on edge devices, such as smartphones and IoT sensors, enables real-time data processing and decision-making without relying on centralized cloud servers. This approach reduces latency and enhances privacy. TinyML frameworks and models like Phi-3-mini, designed to run efficiently on consumer hardware, are driving this trend, with recent benchmarks showing optimized edge models achieving 85-90% of the performance of their larger counterparts while using a fraction of the computational resources.
- Continuous Learning and Adaptation
The shift from static to continuously updated models is gaining momentum. Systems capable of learning from new data and adapting to changing environments without complete retraining are becoming essential for practical AI deployments. Meta’s recent research on parameter-efficient fine-tuning techniques like LoRA (Low-Rank Adaptation) and QLoRA have significantly improved continuous model adaptation, requiring as little as 5% of the resources needed for full model retraining.
The Impact of Open-Source AI Optimization
The proliferation of open-source AI optimization tools and models is democratizing access to advanced AI capabilities. Organizations of all sizes can leverage these resources to develop sophisticated AI applications without substantial investment in proprietary technologies. This accessibility fosters innovation, accelerates development cycles, and promotes a collaborative ecosystem where knowledge and advancements are shared freely.
Recent industry reports from Gartner and Forrester indicate organizations leveraging open-source AI optimization tools experience up to 40% reductions in deployment costs and 50% faster time-to-market for AI applications. The vibrant open-source community surrounding tools like Hugging Face’s Transformers library and OpenAI’s Triton language for GPU programming has accelerated innovation, with model optimization techniques evolving at unprecedented rates.
Conclusion
The rise of open-source AI model optimization signifies a transformative shift in the AI landscape. By embracing solutions like Paiton, organizations can achieve significant performance gains, reduce costs, and contribute to a vibrant community of innovation. As computational efficiency becomes increasingly critical for deploying advanced AI capabilities at scale, tools that maximize hardware utilization will play a central role in the next wave of AI transformation.
Hardware innovations announced at GTC 2025, such as NVIDIA’s Rubin AI chip, alongside software advancements like Tencent’s T1 reasoning model, demonstrate an industry increasingly focused on efficiency and optimization as key differentiators. This aligns perfectly with Paiton’s mission to maximize AI performance across diverse hardware platforms.
The future of AI belongs not merely to those with the largest models but to those who can run them most efficiently. As open-source optimization techniques continue to evolve, we can expect a democratization of AI capabilities, enabling innovations across industries and applications previously constrained by computational limitations.