
A First Look at Paiton in Action: Deepseek R1 Distill Llama 3.1 8B
Outperforming Stock Models on the AMD MI300X 1. Introduction We couldn’t wait to show what Paiton can really do. After…

Short summary: We benchmarked Paiton with our new MoE support on Qwen/Qwen3-30B-A3B-Instruct-2507 to compare inference performance across several setups. Each configuration was run five times per batch size and we report the mean across runs. Why this benchmark Most published numbers use synthetic prompts or toy datasets. We focused on realistic conversational workloads (we always do) to highlight true latency…
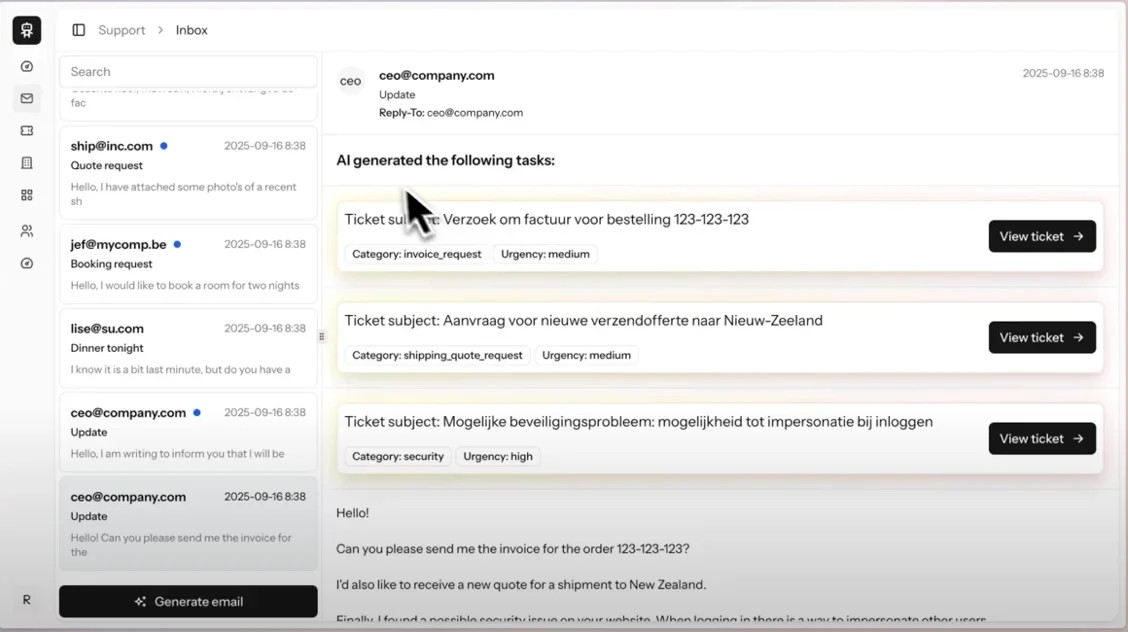
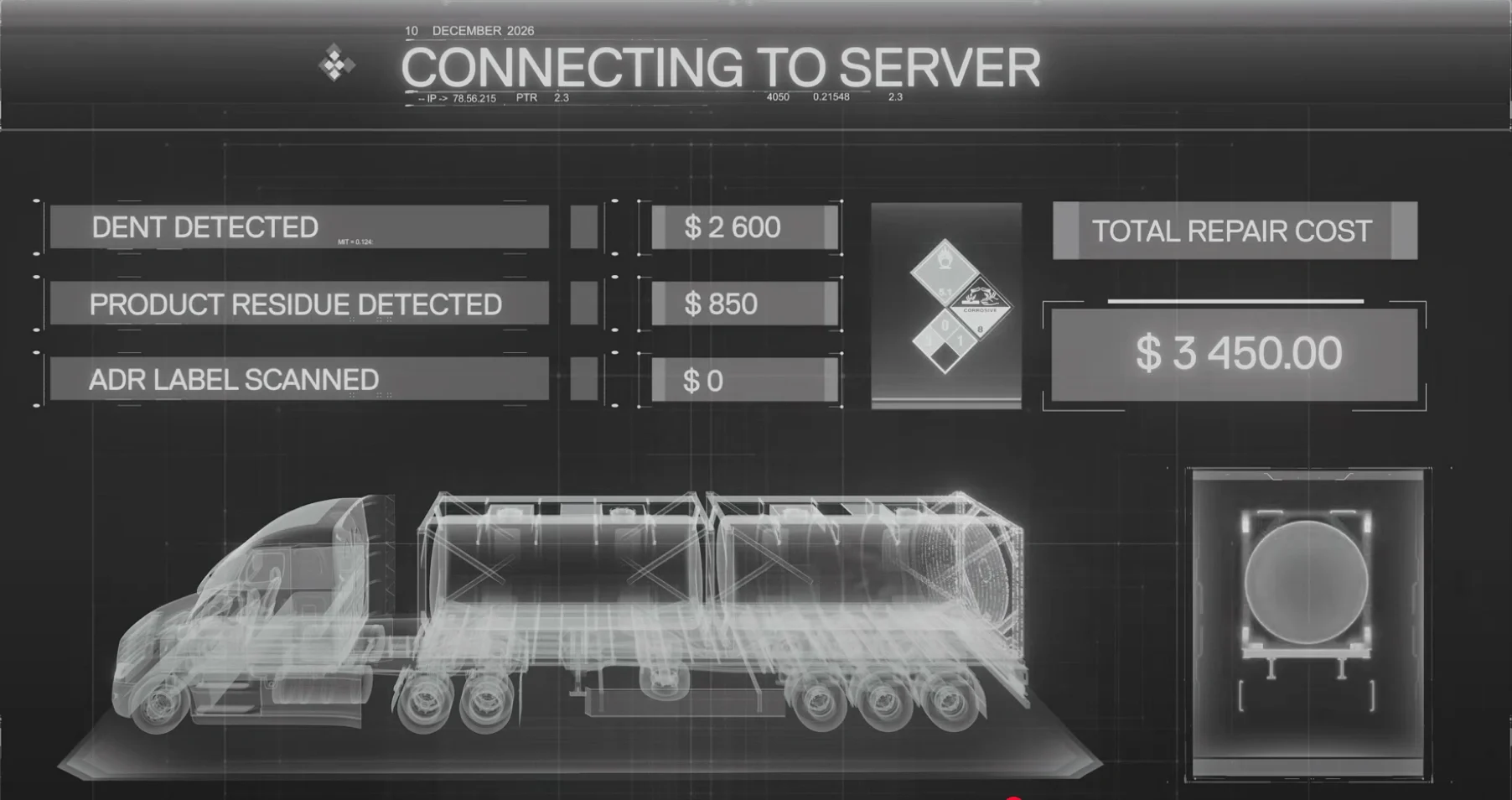
(Nederlandse versie) We’ve built production-ready, local-first agentic AI that plugs into your existing email stack, auto-creates tickets, classifies messages, extracts multi-question threads, reads PDFs, spots invoices/quotes, analyzes images (yes, damage detection), and pushes structured reports into your systems, no dependency on OpenAI, Google, or Microsoft unless you want it. Tailor-made models trained on your data, on your hardware, inside your…
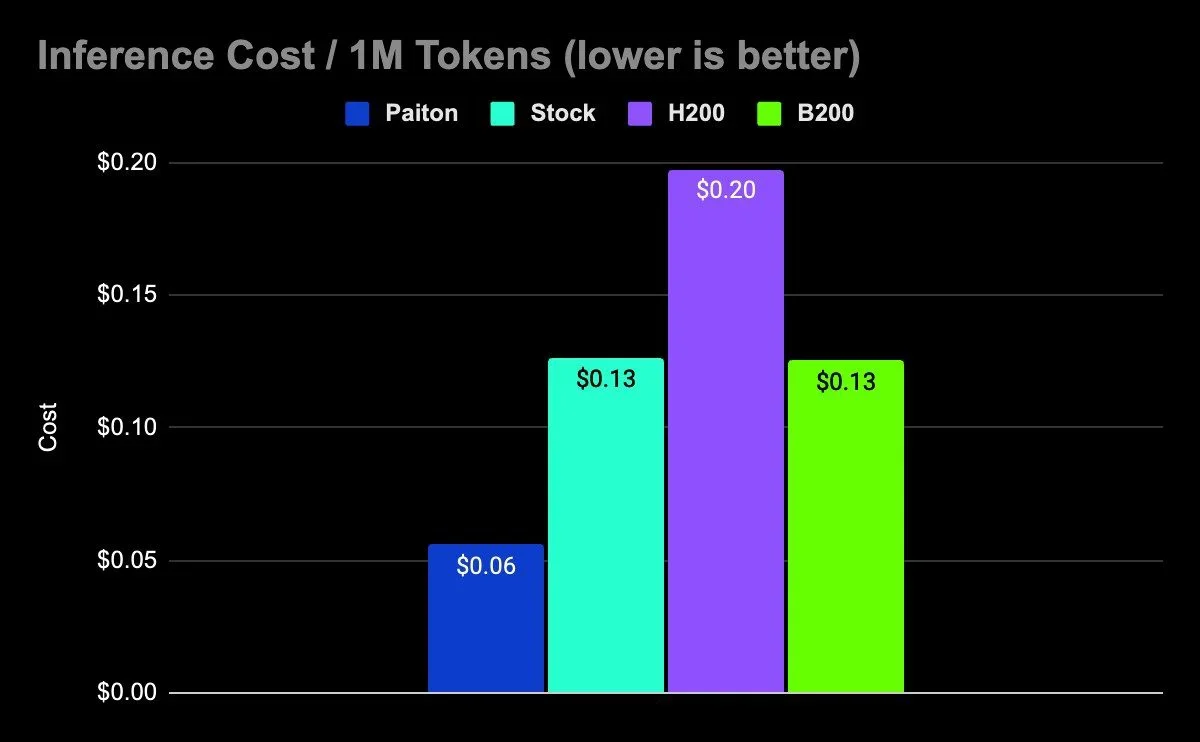
At ElioVP, we’re all about pushing AI inference past the limits, and packaging every squeeze of performance into a plug‑and‑play runtime. Remember our last blog, where Paiton’s FP8 pipeline on AMD’s MI300X completely outclassed NVIDIA’s H200? Well, buckle up, because we’ve gone back to the drawing board. This time, we’re loading Llama-3.1-8B-Instruct-FP8-KV, the leaner, meaner FP8‑quantized Llama variant, into not…
Outperforming Stock Models on the AMD MI300X 1. Introduction We couldn’t wait to show what Paiton can really do. After…

In the fast-paced world of artificial intelligence, model efficiency and performance are paramount. At ElioVP, we’re redefining what’s possible by…