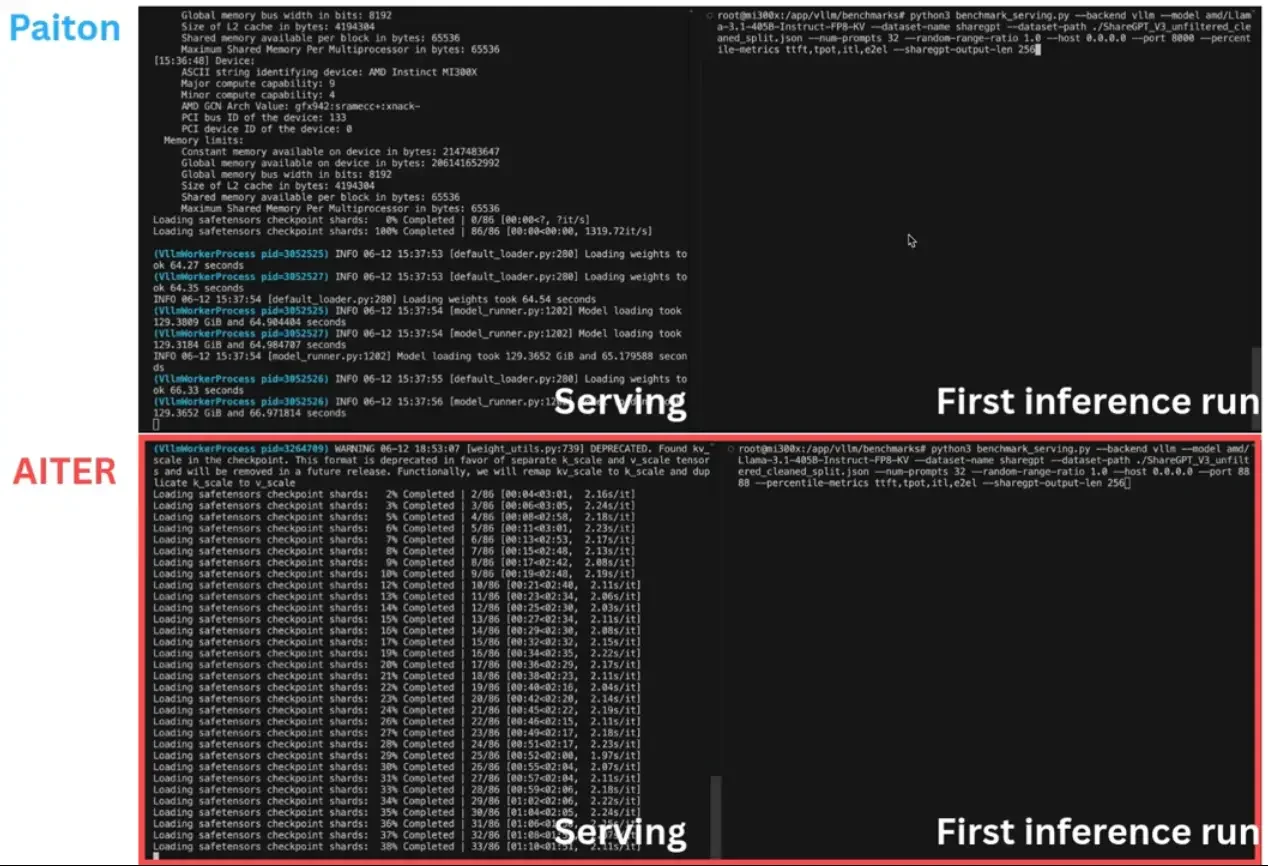
Further Optimizing AMD-Powered Inference with Paiton
Executive Summary
If you’ve followed our journey so far, you’ll know that Paiton is laser-focused on AMD-centric inference optimization. Our latest work takes DeepSeek R1 Distill Llama 8B to the next level, delivering 10–15% higher throughput, improved time-to-first-token (TTFT), and more stable performance at lower batch sizes, an area that previously needed a boost.
- Core Gain: Up to 10–15% improvement in Requests/s and token throughput vs. stock vLLM at batch size 32.
- Lower TTFT: ~12.95% faster mean TTFT, critical for user-facing scenarios like chatbots.
- New Benchmark Tool: A custom approach for orchestrating and measuring performance across multiple AMD MI300 GPUs, ensuring real-world reliability.
In short, Paiton further cements its ability to exploit AMD hardware’s raw power, bridging the performance gap in a landscape that’s sometimes overshadowed by NVIDIA solutions.
DeepSeek R1 Distill Llama 8B Optimization: The Next Chapter with Paiton & AMD
Why Revisit DeepSeek R1 Distill Llama 8B?
- Targeted Gains: Our initial optimizations were strong at higher batch sizes, but lower batch sizes showed room for improvement.
- Broader Real-World Impact: Many users run medium or small batches in production (e.g., 16–128), so we wanted to lift performance across the board.
- Incremental Advances: Building on the foundation we shared in our earlier A First Look at Paiton in Action blog post, we’re now honing those kernels for an even sharper competitive edge.
How We Pushed Efficiency Even Further
- GEMM Optimizations
- We streamlined matrix multiplications (GEMM) to reduce overhead, crucial for transformers.
- Coalesced memory accesses, minimized kernel-launch latencies, and leveraged AMD’s HBM more effectively.
- Refined Kernel Execution
- By analyzing concurrency “hotspots,” we merged or reordered certain GPU kernels, ensuring minimal idle cycles.
- Focused especially on batch size 32, a common real-world concurrency setting for LLM inference.
- Lower Batch Size Focus
- We identified inefficiencies at small batch sizes; new code paths handle them more gracefully, improving TTFT and overall throughput.
Pro Tip: For an overview of the broader improvements we’ve carried out, see our AI Model Optimization with Paiton blog post.
Benchmarking Setup & Methodology
- Hardware Environment
- AMD MI300X GPUs in our research data center.
- Port and concurrency controlled via vLLM’s online mode to mimic real serving scenarios.
- Serving & Benchmark Tools
- vLLM (stock) with:
- CUDA Graph turned on (except we disable Triton for Flash Attention).
- num_sched_prompts increased for concurrency.
VLLM_USE_TRITON_FLASH_ATTN=0for improved stability/perf reasons.
- Paiton injected into vLLM for direct apples-to-apples comparison.
- Our New Benchmarking Tool:
- Built on dstack for orchestrating multi-developer usage.
- Checks GPU availability, preventing resource conflicts.
- Outputs a standardized table of metrics (Requests/s, TTFT, E2E Latency, etc.).
- vLLM (stock) with:
- Primary Metric:
- We emphasize Requests/s and Output Tokens/s, key metrics for users running real-time or near-real-time inference.
- Time-to-First-Token (TTFT) is also critical for user experience.
Here, we’ll showcase a video preview of our benchmark tool in action. The frontend isn’t exactly a masterpiece.. because, well, it was made by our backend engineer.. but it gets the job done!
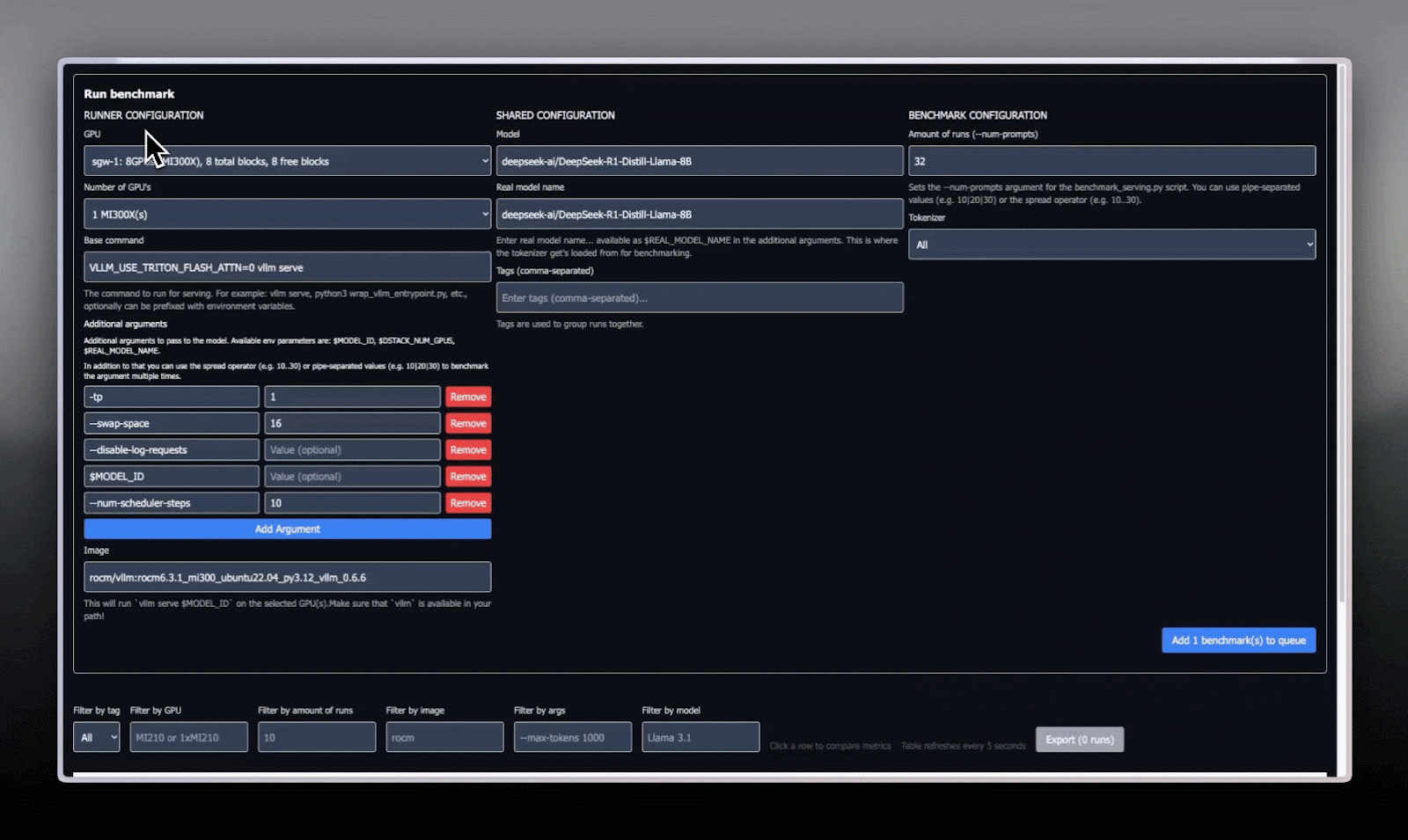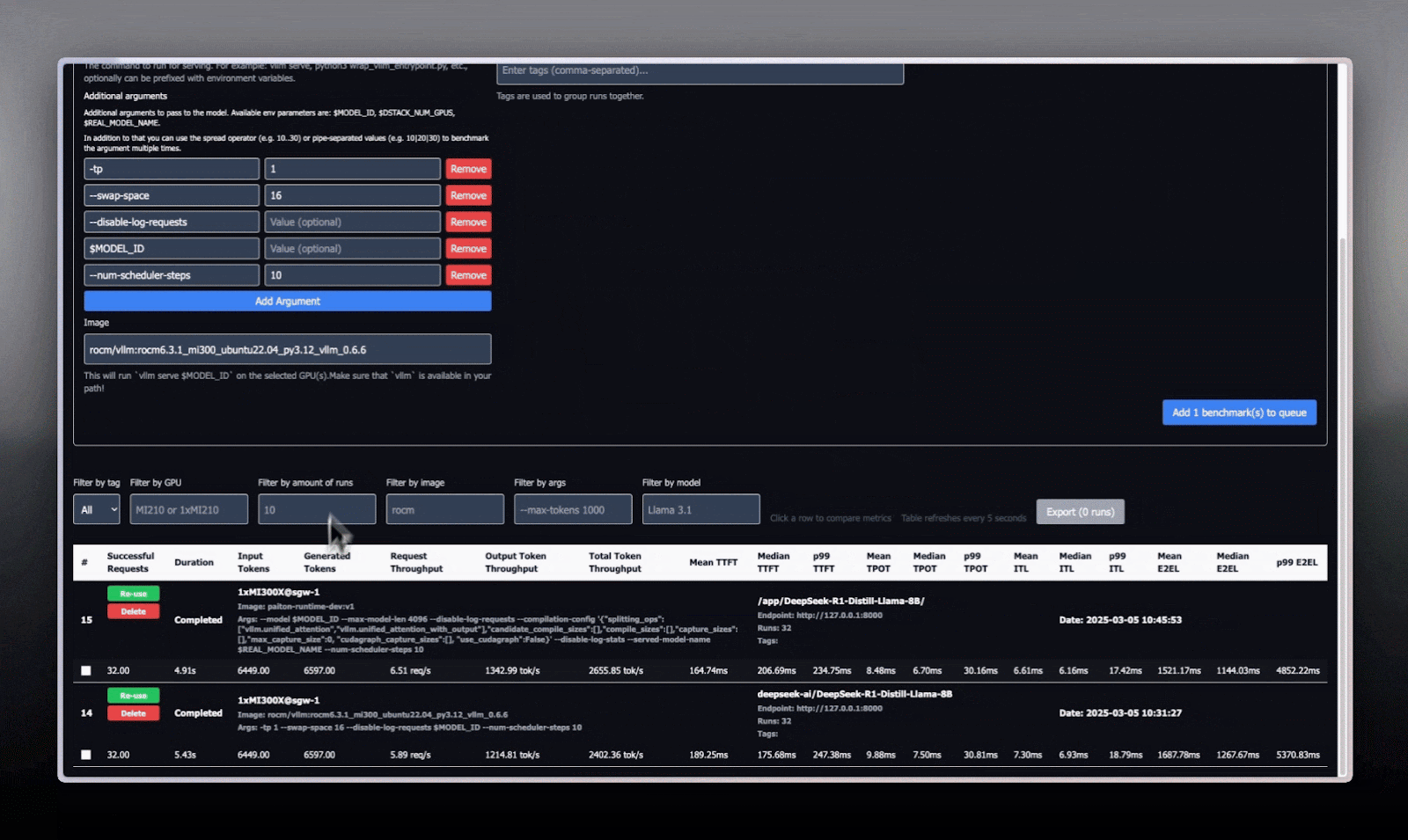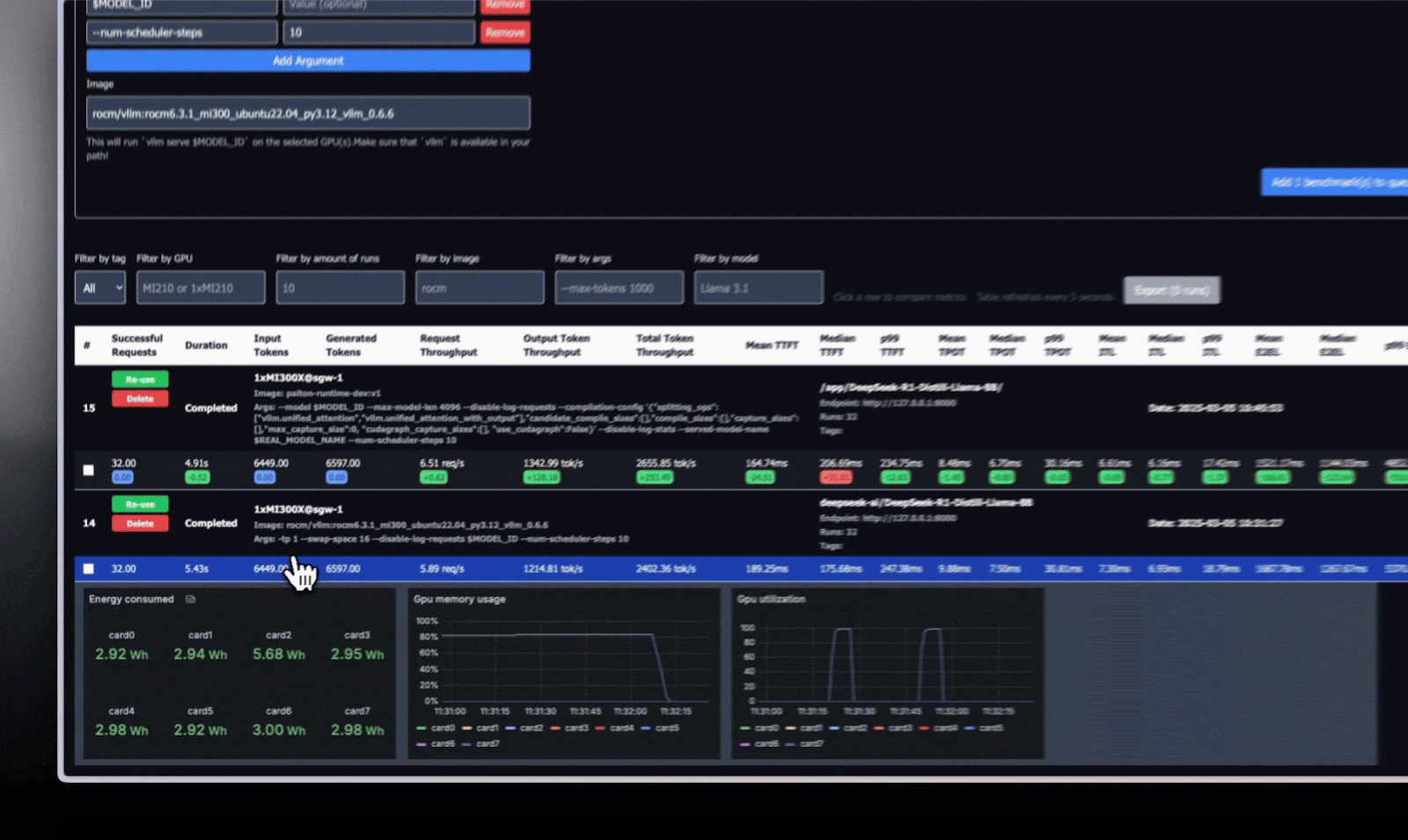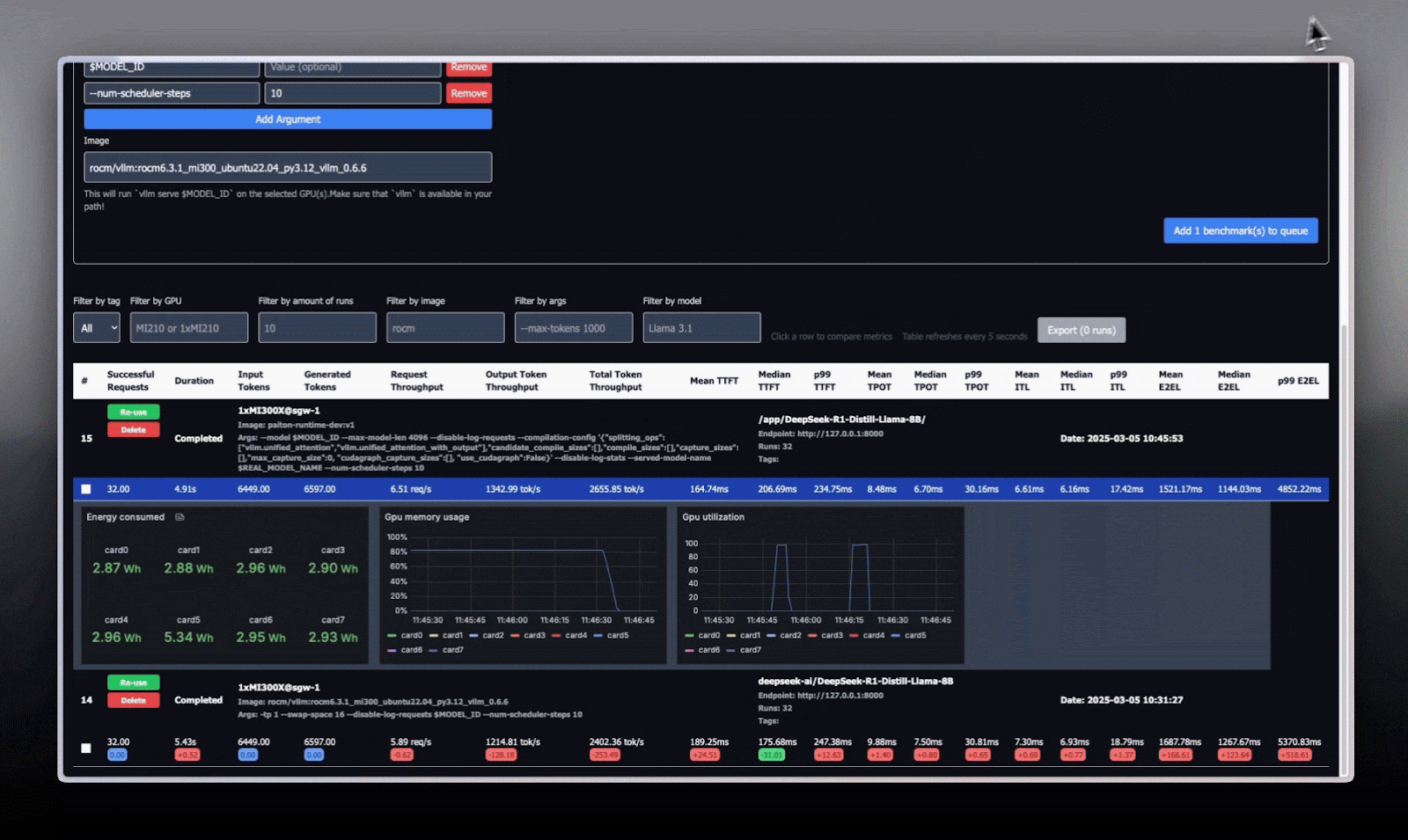
Key Results: Stock vLLM vs. Paiton
Below is a condensed version of our benchmark table at batch size = 32, a prime environment for many real-world deployments:
| Metric | Paiton-vLLMDeepSeek-R1-Distill-Llama-8B | Stock-vLLMDeepSeek-R1-Distill-Llama-8B | % Improvement |
| Successful Requests | 32 | 32 | 0.00% |
| Duration (s) | 4.91 | 5.43 | 9.58% |
| Request Throughput (req/s) | 6.51 | 5.89 | 10.53% |
| Output Token Throughput (tok/s) | 1342.99 | 1214.81 | 10.55% |
| Total Token Throughput (tok/s) | 2655.85 | 2402.36 | 10.55% |
| Mean TTFT (ms) | 164.74 | 189.25 | 12.95% |
| p99 TTFT (ms) | 234.75 | 247.38 | 5.11% |
| Mean TPOT (ms) | 8.48 | 9.88 | 14.17% |
| p99 TPOT | 30.16 | 30.81 | 2.11% |
| Mean ITL (ms) | 6.61 | 7.30 | 9.45% |
| p99 ITL | 17.42 | 18.79 | 7.29% |
| Mean E2EL (ms) | 1521.17 | 1687.78 | 9.87% |
| p99 E2EL | 4852.22 | 5370.83 | 9.66% |
Highlights:
- Throughput up by 10–15%.
- Mean TTFT ~13% faster.
- Total token throughput is consistently higher, meaning both input + output tokens are processed more rapidly.
For a full breakdown of batch sizes from 16 to 256, see the graph below or our raw logs in the next post.
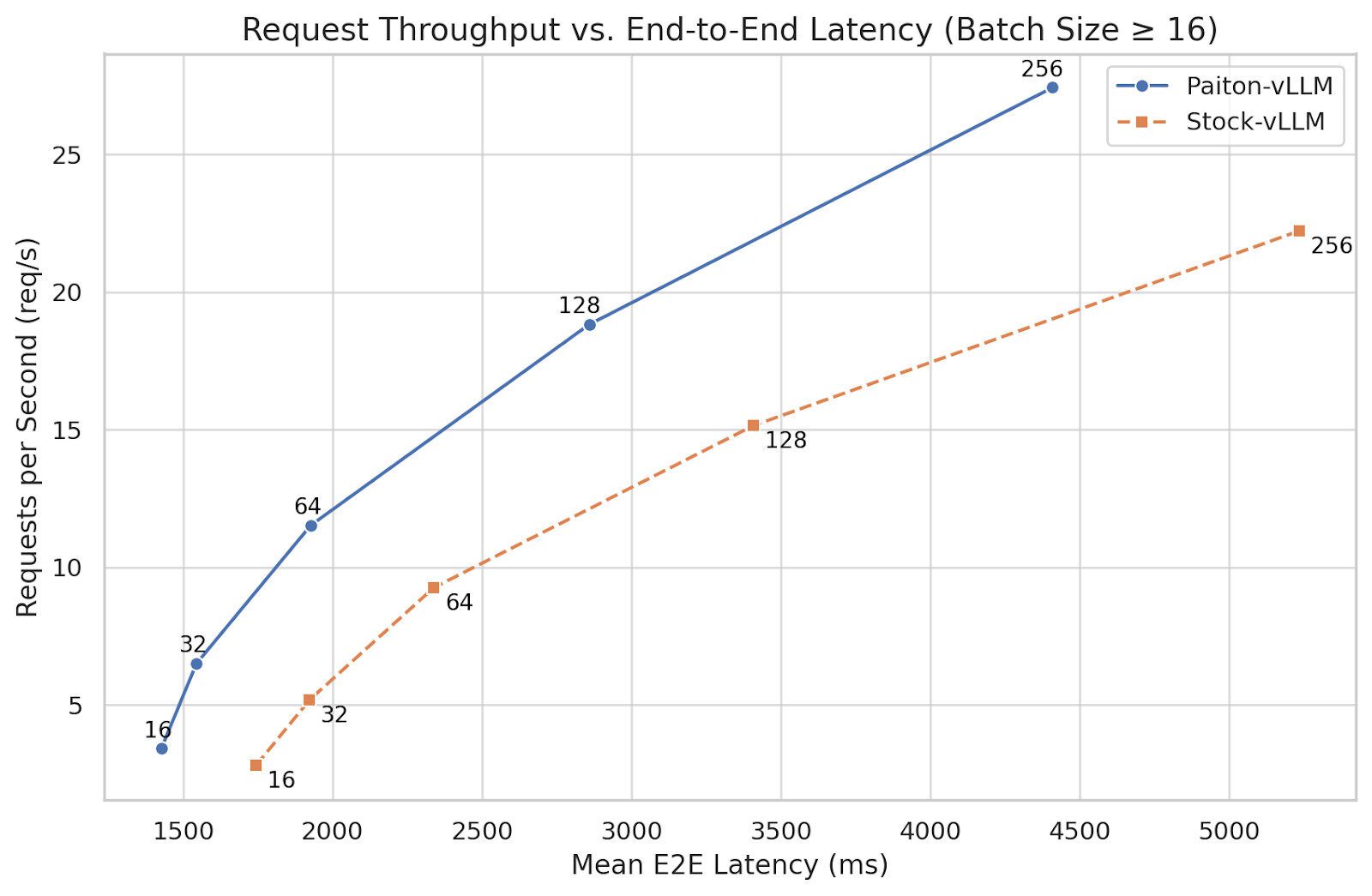
Requests vs. End-to-End Latency
Here is our throughput vs. E2E latency graph for batch sizes 16 to 256, commonly used in production. As you can see, Paiton consistently shifts the curve up and to the left, offering higher throughput and lower latency.
Real-World Use Cases
- Chatbots / Q&A: Faster TTFT is crucial for user satisfaction, ~13% quicker first tokens can be the difference between a “responsive” or “laggy” experience.
- Medium-Batch Deployments: Many enterprise workloads run batch sizes ~32–128 for concurrency. Paiton’s new improvements target precisely these “sweet spot” scenarios.
- Latency-Sensitive Inference: E2E latencies are significantly reduced (mean E2EL ~9.87% better), enabling near real-time responses even under moderate loads.
What’s Next?
- Beyond LLaMA: We plan to adapt these optimizations for other major LLM families, plus initial steps for image/video generation.
- Tensor Parallelism: True multi-GPU support is on our radar, Paiton will seamlessly allow large model inference across multiple AMD GPUs.
- Quantization: Minimizing precision while retaining accuracy will further shrink latencies and allow a certain popular model to be used..
As we like to say: “We’ll come for you, and we will optimize you!” Our focus remains on relentlessly refining, optimizing, and redefining what’s possible on AMD GPUs.
Conclusion
Paiton continues to evolve, and DeepSeek R1 Distill Llama 8B stands as a shining example of how AMD hardware can truly excel when matched with carefully honed software. Our new results showcase 10–15% improvements at key batch sizes, with consistent performance gains across throughput, latency, and token-level metrics.
Stay tuned as we extend these optimizations to broader LLM families and Image/Video Gen models. If you have specific requests, or if you’d like to see these optimizations at even larger batch sizes, let us know, we’d love to dive deeper.
Additional details will appear in our upcoming deep-dive post, focusing on how dstack plus our custom benchmark tool orchestrate multi-developer testing and benchmarking without friction.
Thanks for reading and see you in the next optimization update!
– The Paiton Team –