Paiton: The Simplest Way to Supercharge AI Inference
Let’s be honest, we’re not the marketing type.
We’ve never taken a cent of outside investment, never burned cash on ad campaigns, and never hired a sales army.
We just build things that work.
In today’s world, it seems the companies shouting the loudest often get the spotlight, while the ones doing the actual engineering quietly build the future.
We’re the latter.
Still, after a friendly nudge from someone who actually knows marketing, we were told:
You guys should brag, the results are obvious and you’ve earned it.
So… here we go. 😉
The Smarter Way to Get Faster
In a market flooded with “revolutionary” engines and new runtimes, Paiton takes a simpler, smarter path.
It’s not another inference engine, it’s a performance amplifier for the one you already use.
With Paiton, you don’t need to re-download your models, migrate your stack, or reconfigure your infrastructure.
You just plug it in, and watch your throughput jump.
If you’re using vLLM or SGLang, you’re already compatible.
Plug In, Power Up
Paiton slots right into your existing environment due to it being completely engine agnostic.
No new APIs. No retraining. No learning curve.
| Engine Stack | Setup Change | Model Support | Typical Speedup | Compatibility |
| Paiton + vLLM | None | Always | +25–40% | 100% |
| Custom Engine | High | Not Always | +20–30% | Limited |
| Standard vLLM | None | Always | Baseline | 100% |
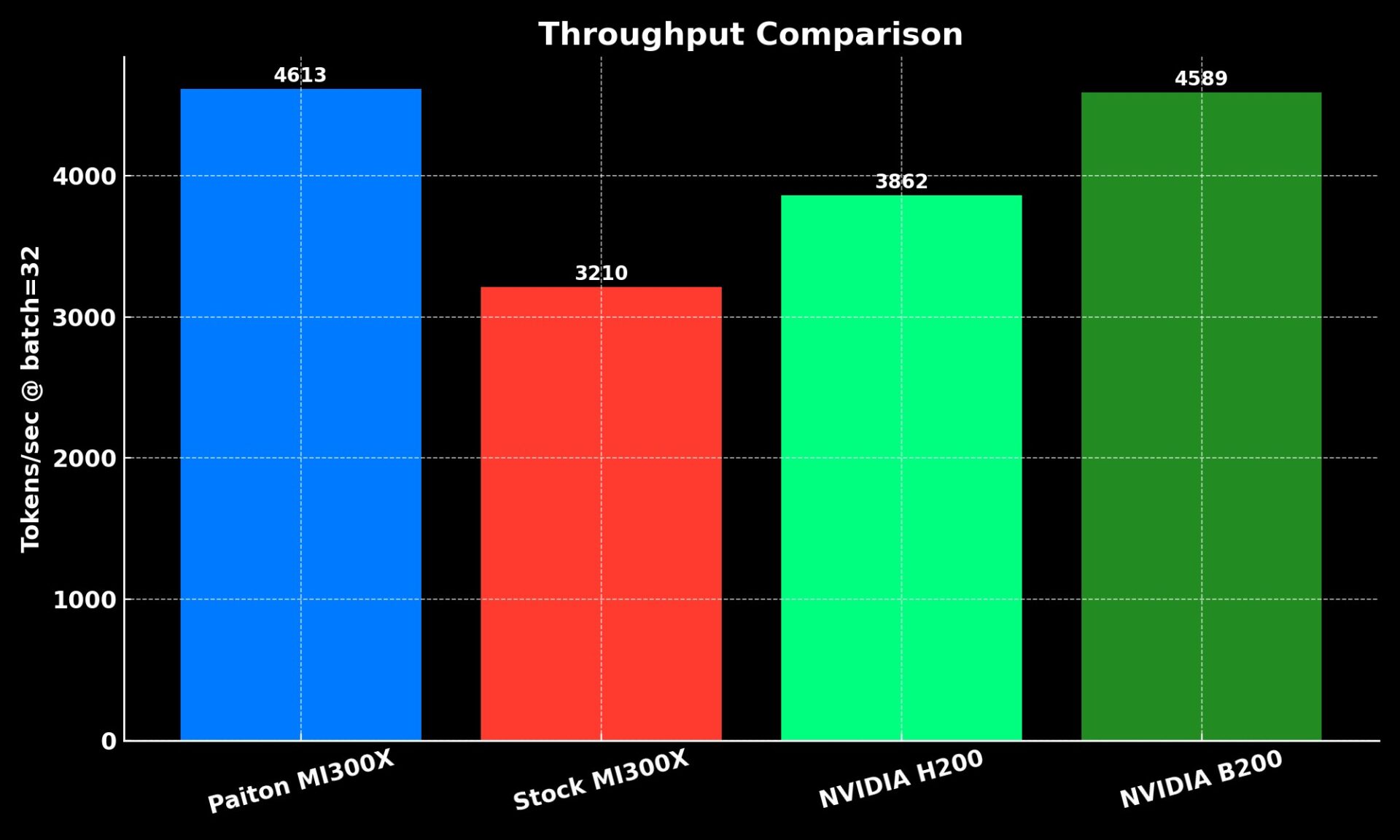
Real Performance. Real ROI.
We focused our energy where it matters, deep kernel fusion, custom GEMMs, and optimized inter-GPU communication.
The result: AMD MI300X with Paiton outperforms newer GPUs that cost significantly more, while running on your existing stack.
Performance per Dollar
| Hardware | Framework | Tokens/sec | Perf per $ (H200 = 1.0) | Result |
| NVIDIA H200 | vLLM | 3,862 | 1.00 | Baseline |
| NVIDIA B200 | vLLM | 4,589 | 0.82 | Slight bump, lower efficiency |
| Stock MI300X | vLLM | 3,210 | 1.43 | Strong |
| AMD MI300X + Paiton | vLLM / SGLang | 4,613 | 2.07 | Winner |
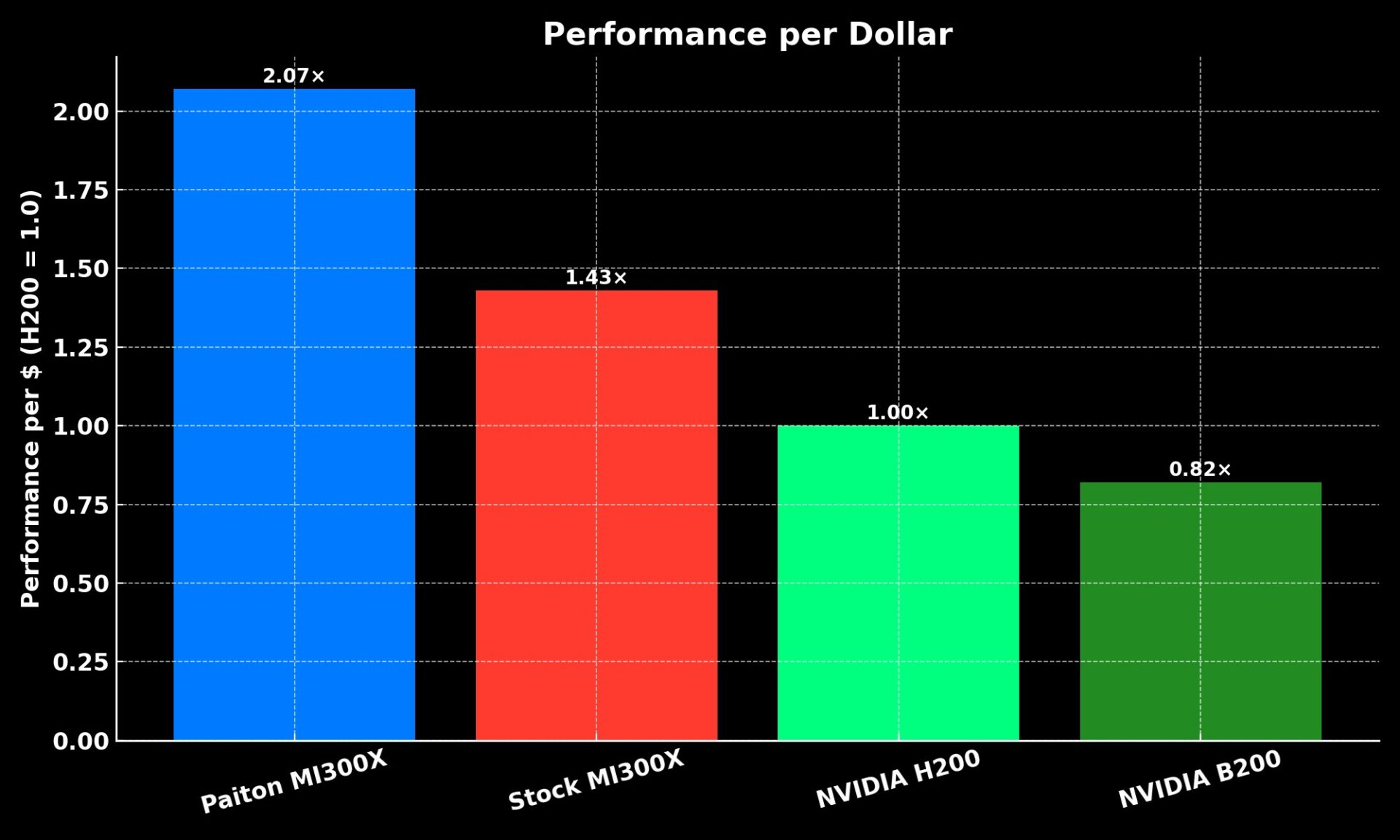
Real-world efficiency: Paiton MI300X delivers over 2× the performance-per-dollar of NVIDIA H200.
Meaning: You get 40–50% higher performance at nearly half the cost per token, without changing your stack.
Keep Your Stack. Keep Your Models. Just Go Faster.
Other tools promise performance but force you to rebuild everything.
Paiton simply optimizes what you’re already running.
| Feature | Standard Stack | Custom Engine | Paiton |
| Model File Compatibility | Native | Often Requires Conversion | Native |
| Engine Migration | Needed | Required | None |
| Stack Maintenance | Normal | High | Low |
| Immediate ROI | Medium | Slow | Instant |
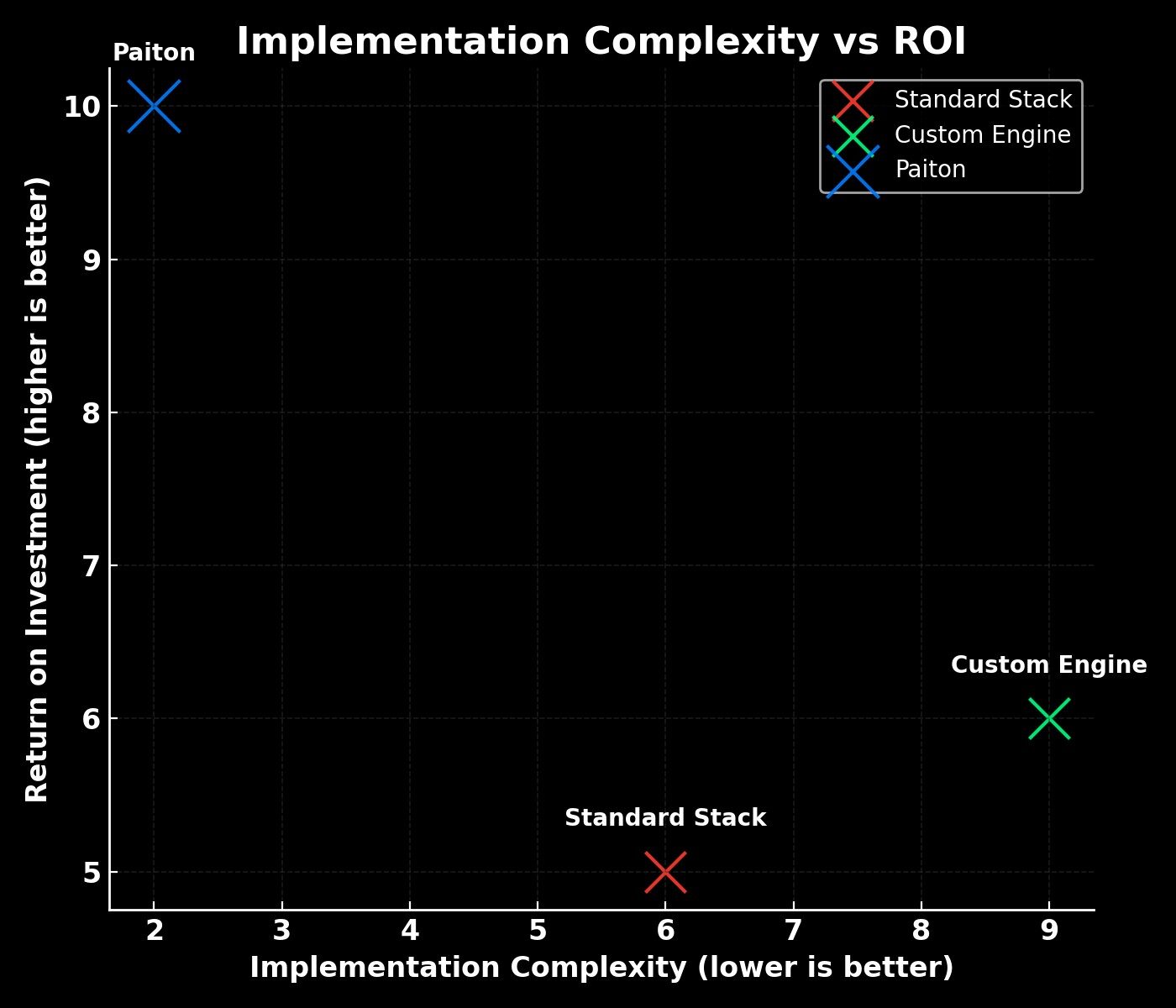
Paiton sits in the “sweet spot”: lowest complexity, highest ROI.
The Business Math
Every millisecond shaved off inference time translates into real savings.
Here’s what that looks like in practice, based on real-world data from our own Qwen3-30B benchmarks:
Cost per 1M Tokens (USD)
| Setup | Cost per 1M Tokens | Efficiency Gain |
| NVIDIA H200 | $0.186 | — |
| NVIDIA B200 | $0.227 | -22% |
| Stock MI300X | $0.130 | +43% |
| Paiton MI300X | $0.090 | +51% |
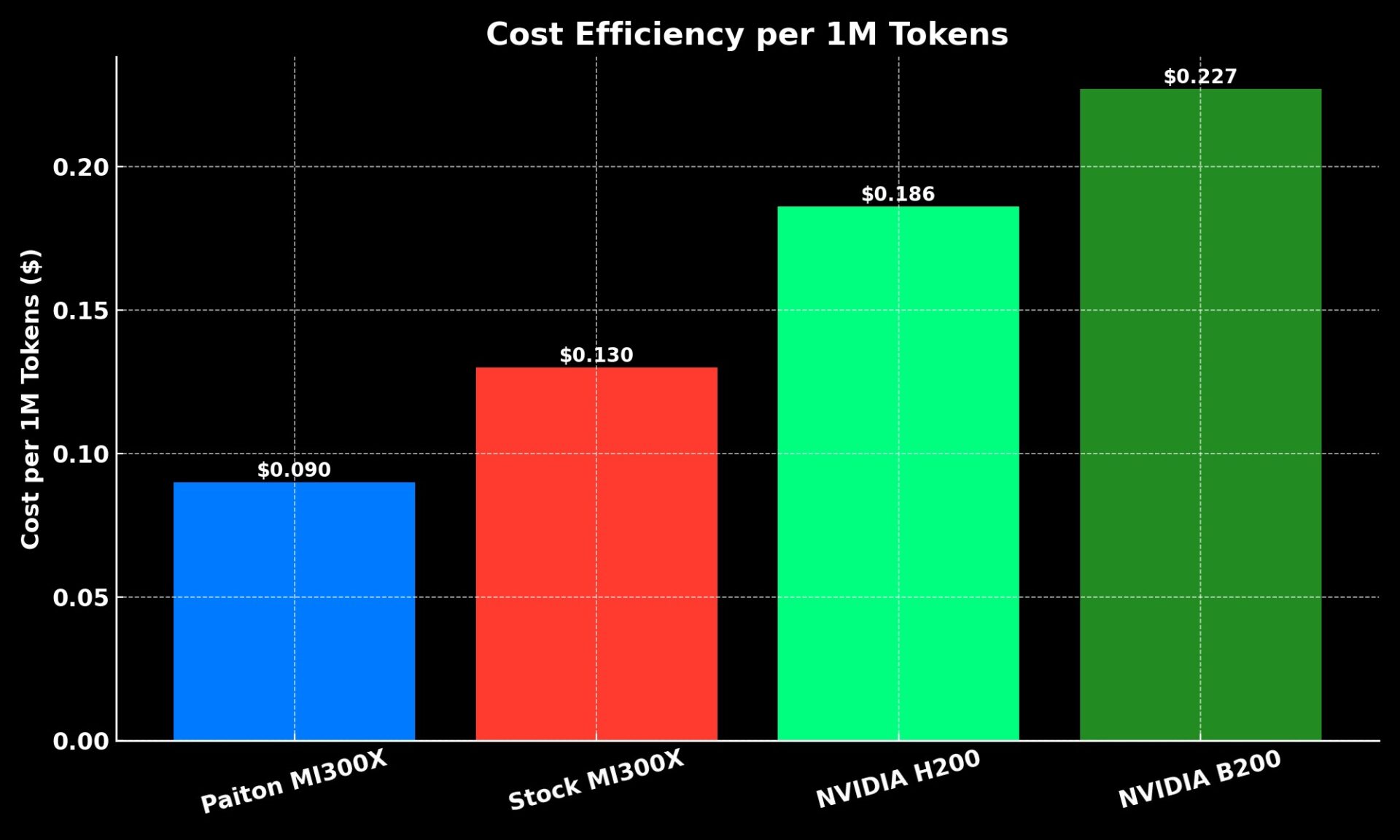
Paiton cuts inference cost per million tokens by nearly half compared to H200.
Result: Faster inference, lower costs, and immediate ROI.
Startup Time Matters Too
Inference isn’t everything, startup speed counts, especially for scaling large models.
For Llama-3.1-405B-Instruct-FP8-KV, Paiton drastically reduced cold-start time by 46% overall.
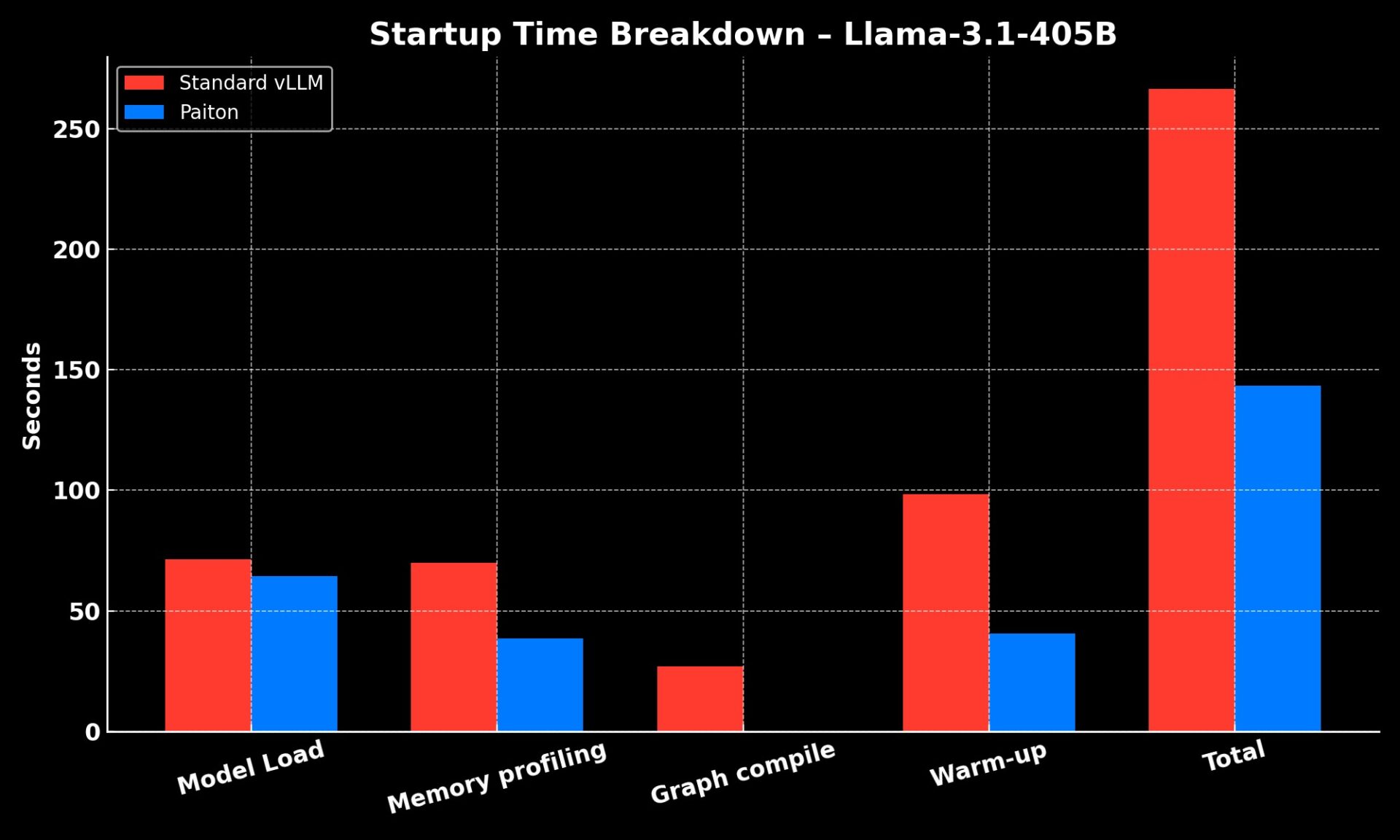
From model loading to warm-up, Paiton slashed startup latency from 266s to 143s, a 46% reduction.
Why It Matters
There’s a myth that to get better performance, you need a new engine.
We disagree.
Paiton proves smarter software beats newer hardware, and you can have both.
No downloads. No friction. Just better results.
The Bottom Line
If you’re running vLLM, SGLang, or any AMD-based deployment, Paiton is the easiest upgrade you’ll ever make.
- No new engine
- No model downloads
- No workflow disruption
- Instant acceleration and lower cost
Faster inference isn’t just a benchmark, it’s a business advantage.
And Paiton is built to deliver it.
Learn more at https://ai.eliovp.com/paiton
Stay Tuned
Make sure to keep an eye on us, we’re not done raising eyebrows just yet.
We’ve been deep in the trenches pushing FP8 optimization to new limits, both static and dynamic, fine-tuned for Mixture-of-Experts (MoE) models.
The early results? Let’s just say they’re borderline unbelievable, and all achieved on AMD hardware, without changing your stack or relying on any proprietary APIs.
Stay tuned, the next drop will redefine what “optimized inference” really means.
Sources / Further Reading
All performance claims in this article are based on our own internal benchmarking (with evaluation models available) on AMD MI300X systems using vLLM/SGLang with Paiton enabled, as documented below: