Field Report. The Reality of Building Agentic AI in 2025
From Hype to Sovereign Infrastructure
Summary
The narrative surrounding “Agentic AI” in 2025 is defined by a sharp contrast between market expectations and engineering reality. While the general public, conditioned by the ease of ChatGPT, expects “miracles” and instant integration, the reality of building autonomous agents for enterprise workflows is a discipline of rigorous engineering, deep architectural planning, and infrastructure sovereignty.
This report details the challenges and methodologies we have encountered while deploying custom, on-premise AI agents. Unlike the majority of the market relying on volatile public APIs, our approach focuses on Sovereign AI, running modular, tailored solutions entirely locally. This strategy mitigates the risks of API crashes, “silent updates” that break prompts, and unpredictable price surges, ensuring that our customers’ solutions remain robust, private, and cost-efficient over the long term.
1. The Expectation Gap and the “Custom” Necessity
1.1 The Miracle Myth vs. Engineering Reality
A pervasive challenge in 2025 is the “over-expectation” of AI capabilities. Clients often approach Agentic AI with the mindset of a chatbot user, expecting a plug-and-play solution that can “magically” navigate their entire ERP system out of the box.
- The Reality. An AI Agent is not a miracle; it is a complex software system that requires defined boundaries.
- The Solution. We build everything modularly. By keeping the architecture component-based, we ensure that as a customer scales or identifies new use cases (e.g., expanding from support ticketing to inventory management), we can integrate new “cognitive modules” without rewriting the core system. This modularity is essential for long-term viability.
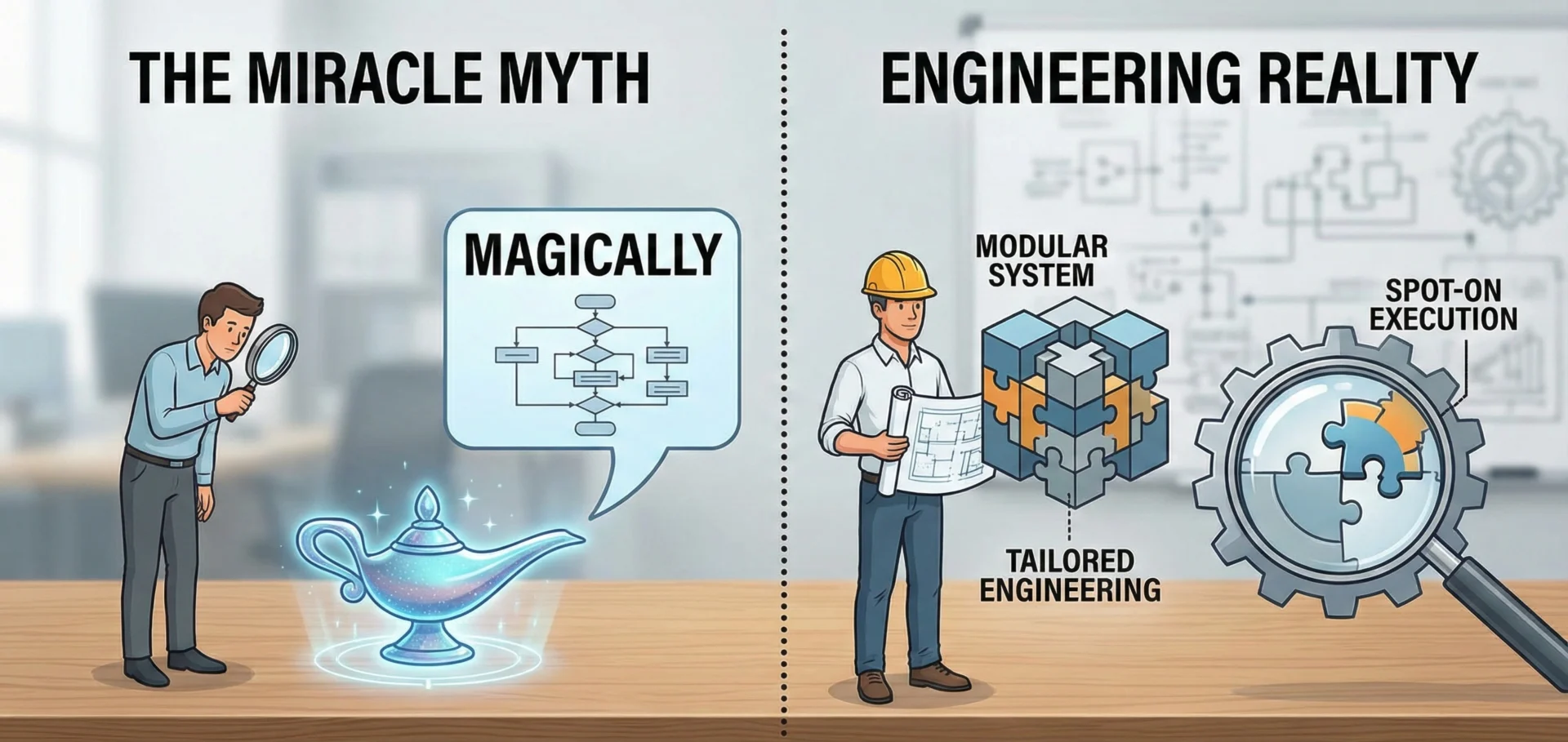
1.2 The Failure of “Global” Solutions
We have realized that building a “global” product that attempts to work for every customer is a trap. Generic agents lack the nuances of specific business workflows, leading to brittle performance and high support overhead.
- Tailored Engineering. Success requires analyzing the customer’s entire workflow, often involving on-site meetings and deep dives into their data structures. A solution tailored to the specific eccentricities of a client’s data will always outperform a generic “one-size-fits-all” model.
- Spot-On Execution. By restricting the agent’s scope to a tailored environment, we reduce the surface area for hallucinations and logic errors, ensuring the solution is “spot on” rather than “generally okay.”
2. The Economics of Agentic AI
2.1 The Cost of Discovery
Because existing AI Agents cannot simply be “implemented” like a standard software library, every project requires a distinct analysis phase.
- Discovery Phase. We invest significant time in pre-development analysis. This includes multiple meetings to map out the “real life” situation of the client’s operations.
- Cost Reality. As detailed in industry analyses, the cost of custom agent development involves hidden factors beyond just coding, including dataset preparation, architecture design, and extensive testing.
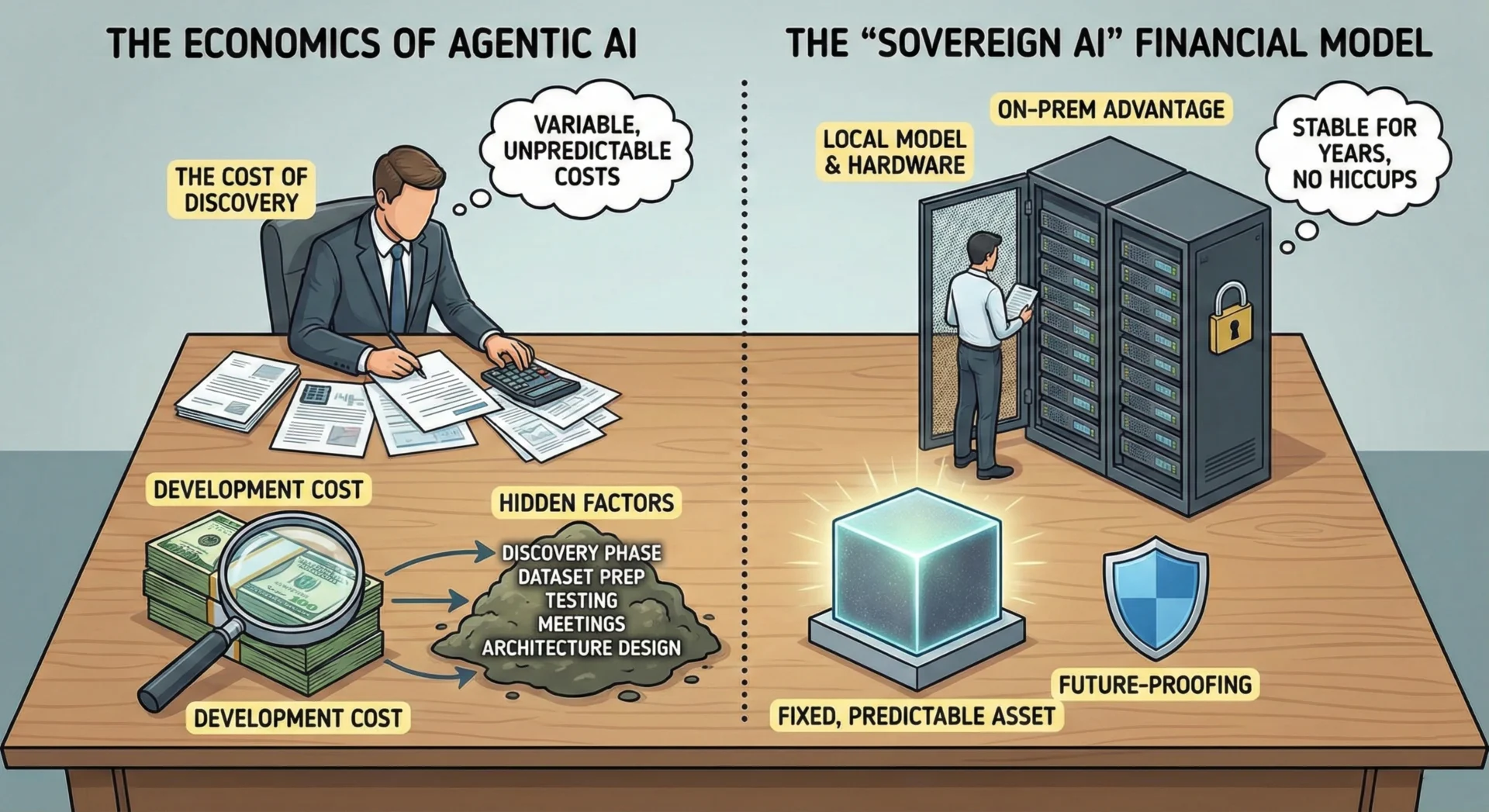
2.2 The “Sovereign AI” Financial Model
We do not utilize the APIs of big providers (OpenAI, Anthropic, etc.). Relying on external APIs introduces existential business risks:
- Volatility. Will the API price suddenly triple?
- Reliability. Will the API crash during peak business hours?
- Drift. Will a “silent model update” break our prompts overnight?
The On-Prem Advantage:
By training and running everything locally (On-Prem), we convert variable, unpredictable costs into fixed, predictable assets.
- Future-Proofing. A local model combined with owned hardware effectively does its job for years without hiccups. It does not get “dumber” because it is “old,” nor does it cost more to run in 2027 than it did in 2025. It is a stable asset.
3. Observability, Debugging, and Hallucinations
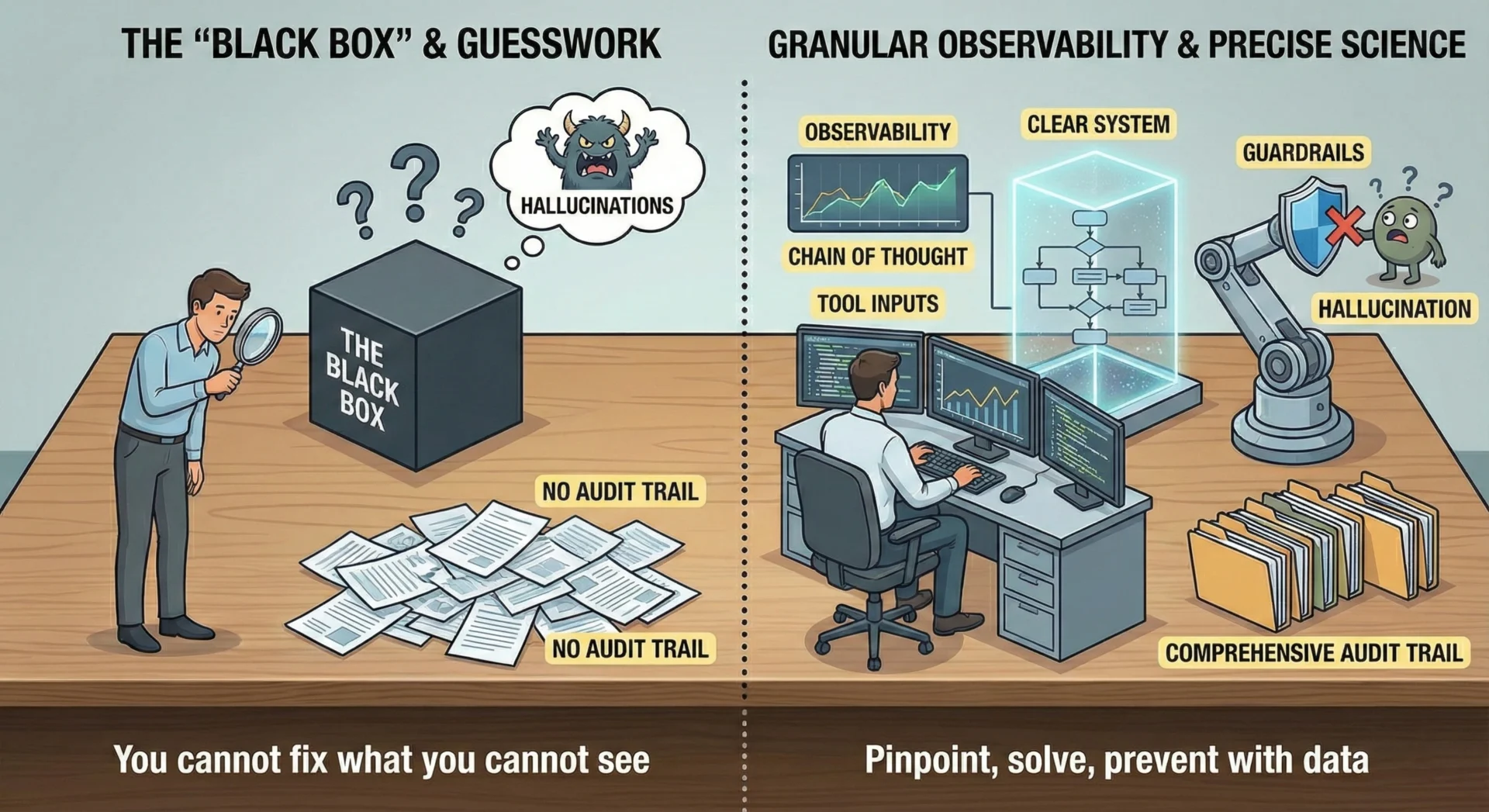
You cannot fix what you cannot see. We pride ourselves on delivering “very nice working solutions,” which mandates granular observability.
3.1 Tracking the “Black Box”
We utilize multiple tools to extensively track the LLM’s decision-making process. Debugging an agentic loop requires seeing the exact “Chain of Thought” and tool inputs that led to a specific action.
- Why we do it. It allows us to pinpoint exactly where an agent got stuck in a loop or failed to retrieve the correct context, transforming debugging from guesswork into a precise science.
3.2 Managing Hallucinations
Hallucinations are an inevitability that must be managed. We log everything. By maintaining a comprehensive audit trail of every input, thought, and output, we can:
- Track. Identify patterns where the model consistently confabulates.
- Solve. Adjust the system prompt or fine-tune the model to eliminate these specific failure modes.
- Prevent. Implement “guardrail” classifiers that block hallucinatory outputs before they reach the user.
3.3 Metadata Strategy for Agentic Search
For agentic search to work, “raw text” is insufficient. We ensure that we save extensive metadata alongside the vector embeddings.
- Contextual Anchoring. An agent analyzing a contract needs to know the date, author, version, and department. Without this metadata, the agent is searching blindly. We engineer our data ingestion pipelines to capture this context automatically, ensuring the agent retrieves not just “similar text,” but “the right document.”
4. The Cognition Layer. Models and Training
4.1 Fine-Tuning is Not Optional
We extensively test open-source models, but they rarely meet our specific expectations out of the box.
- The Reality. To achieve production-grade reliability, we almost always need to fine-tune models on the customer’s specific data. This aligns the model’s “voice” and logic with the customer’s actual business rules.
4.2 Vision. Training from Scratch
For vision-related projects, fine-tuning is often insufficient. We frequently train models from scratch on the customer’s proprietary visual data (e.g., manufacturing defects, document layouts). This ensures the model learns the specific visual features relevant to the client, rather than relying on generic “internet-trained” features.
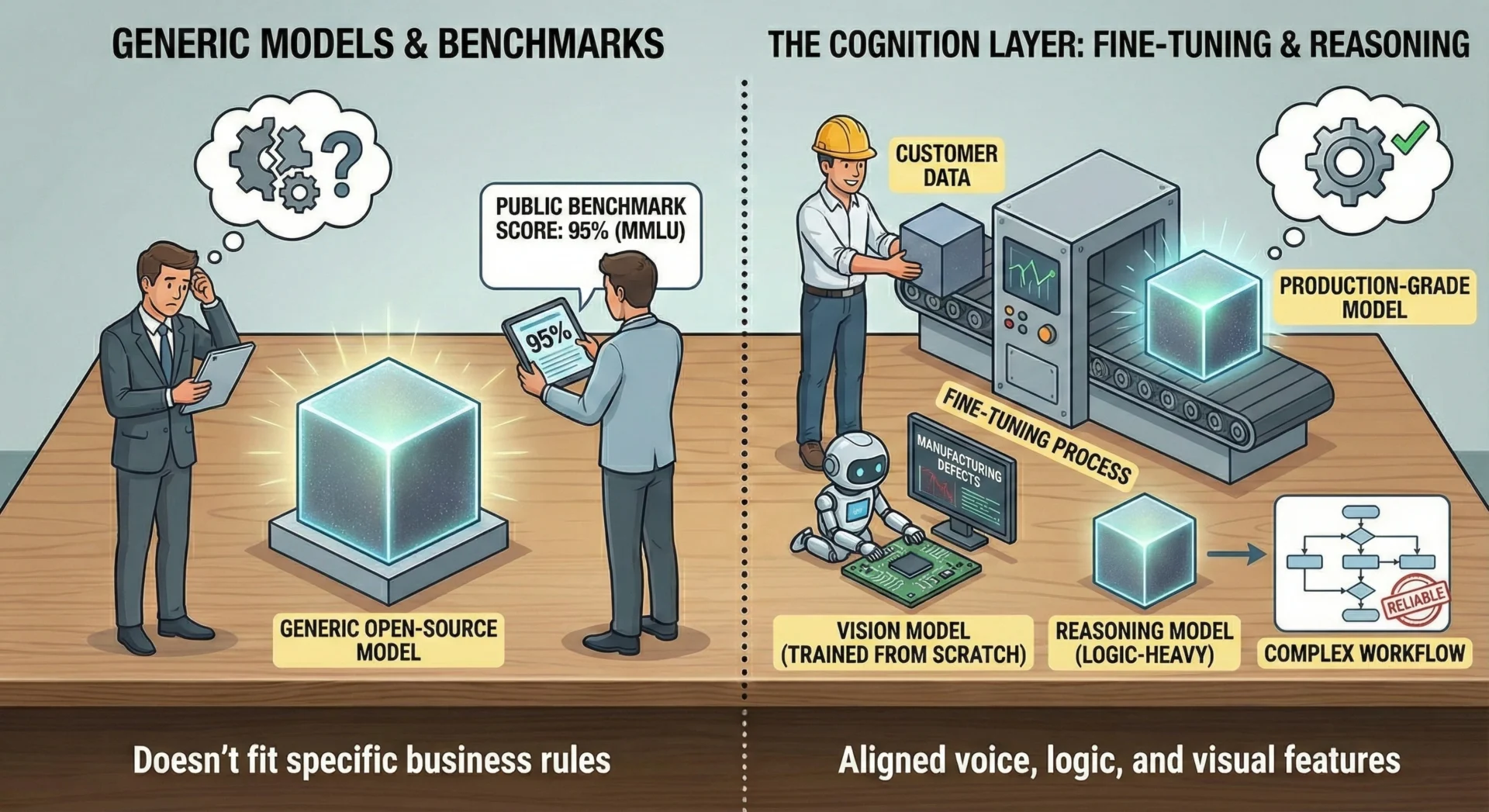
4.3 Reasoning Models and Benchmarks
We have found that reasoning/thinking models (like DeepSeek R1 or similar logic-heavy architectures) are absolutely the better choice for complex agentic workflows.
- Benchmarks aren’t everything. A model might score high on a generic benchmark (like MMLU), but the slightest change in our prompting or workflow can generate a totally different effect. Extensive internal testing often contradicts public leaderboards.
5. Hardware Realities. The VRAM Bottleneck
5.1 The Memory/Context Trade-off
Running “Reasoning Models” locally comes with significant caveats, primarily hardware requirements.
- The “Buffer” Necessity. Context is expensive. Analyzing a single mail thread of 50 emails might consume gigabytes of memory for the KV cache alone.
- The Failure Mode. If this memory buffer is not available, the system hits an Out-Of-Memory (OOM) error, or we are forced to truncate context. When context drops, accuracy drops, and the “AI Agent fails.”
5.2 Quantization. Bigger is Better
We have empirically found that parameter count trumps precision.
- The Rule. A large, quantized model, for example, a 72B parameter model quantized to FP8 (or even lower), often generates much better reasoning results than a smaller 8B model running unquantized (BF16).
- Why. The larger model possesses a deeper “world model” and logic capability that survives quantization, whereas the smaller model, even at high precision, lacks the cognitive depth to handle complex agentic tasks.
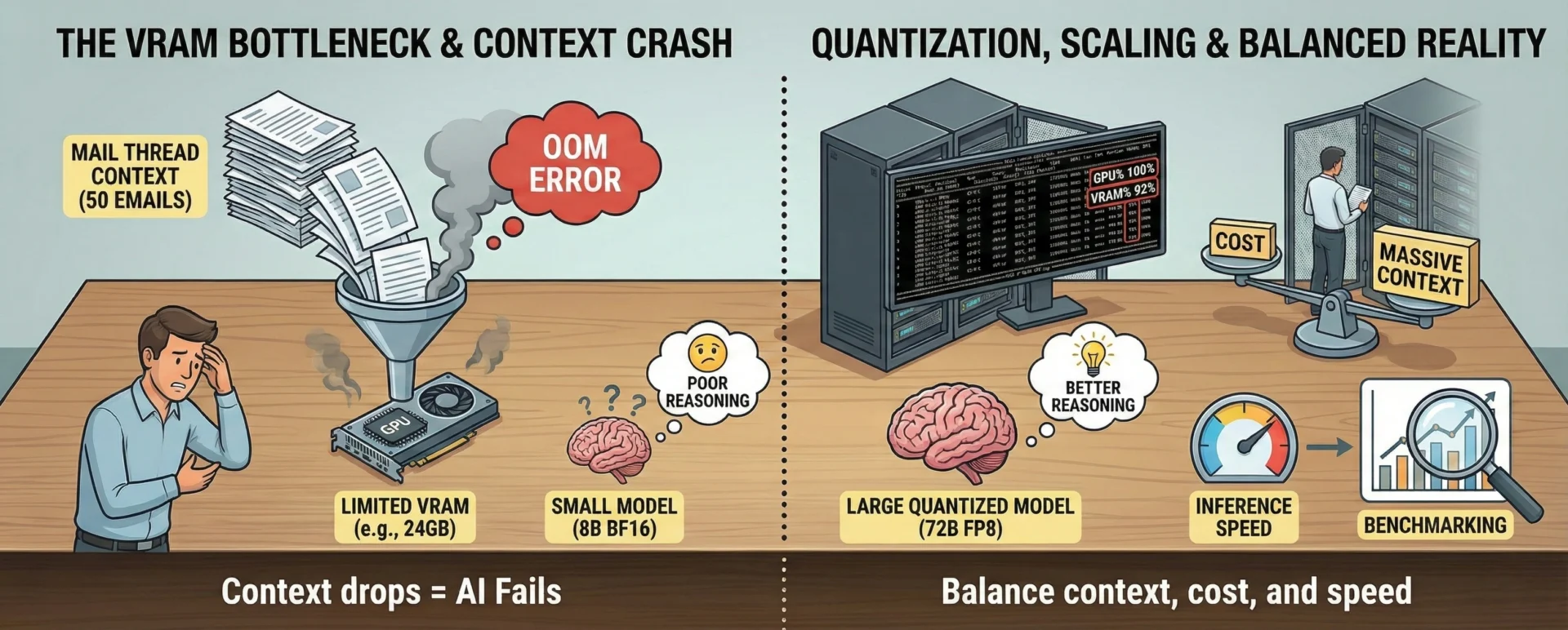
5.3 Scaling and Cost
While we can acquire expensive data center GPUs (B200s/MI355X) with massive memory, these are often prohibitively expensive for mid-size (or even larger) companies.
- The Challenge. We must constantly balance the need for massive context (for reliability) with the budget constraints of on-premise hardware.
- Inference Speed vs. Accuracy. We extensively test quantized versions to see if we can speed up inference and save memory without losing accuracy. It doesn’t just “work out of the box”; it requires rigorous benchmarking per use case.
Conclusion. The Constant Evolution
The market changes extremely fast. New quantization formats, new open-source models, and new agentic frameworks emerge on a daily basis.
- Our Commitment. We have to keep up. We continuously test and improve our workflows to ensure our clients aren’t left behind.
- The Upside. Despite the challenges, the hardware constraints, the data cleaning, the hallucination tracking, we love it. We are building systems that provide genuine, sovereign automation, free from the whims of the big AI providers.
Ready to build your Sovereign AI workforce? If you are looking for a partner to navigate these challenges and build a custom, on-premise solution that you truly own, we are here to help.