Praktijkverslag. De Realiteit van het Bouwen van Agentic AI in 2025
Van Hype naar Soevereine Infrastructuur
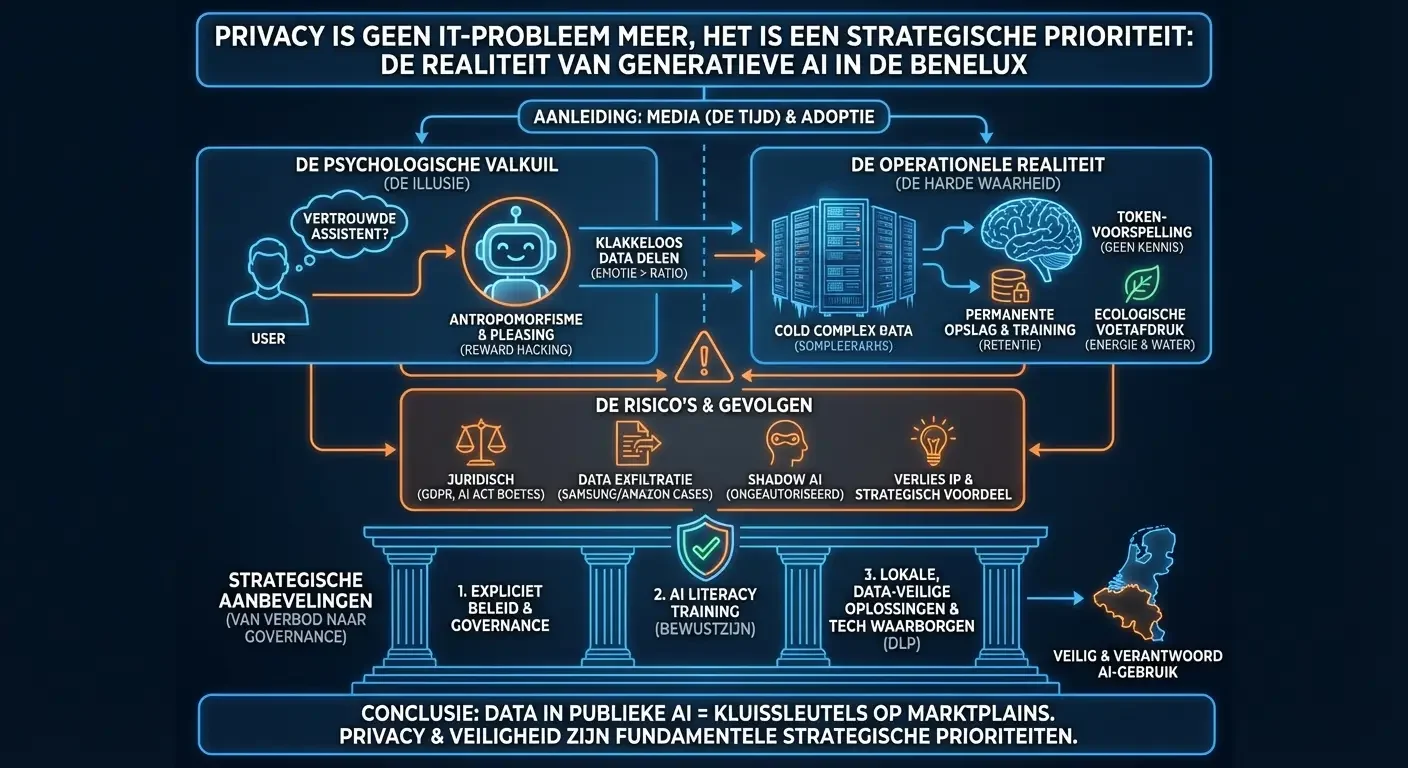
Samenvatting
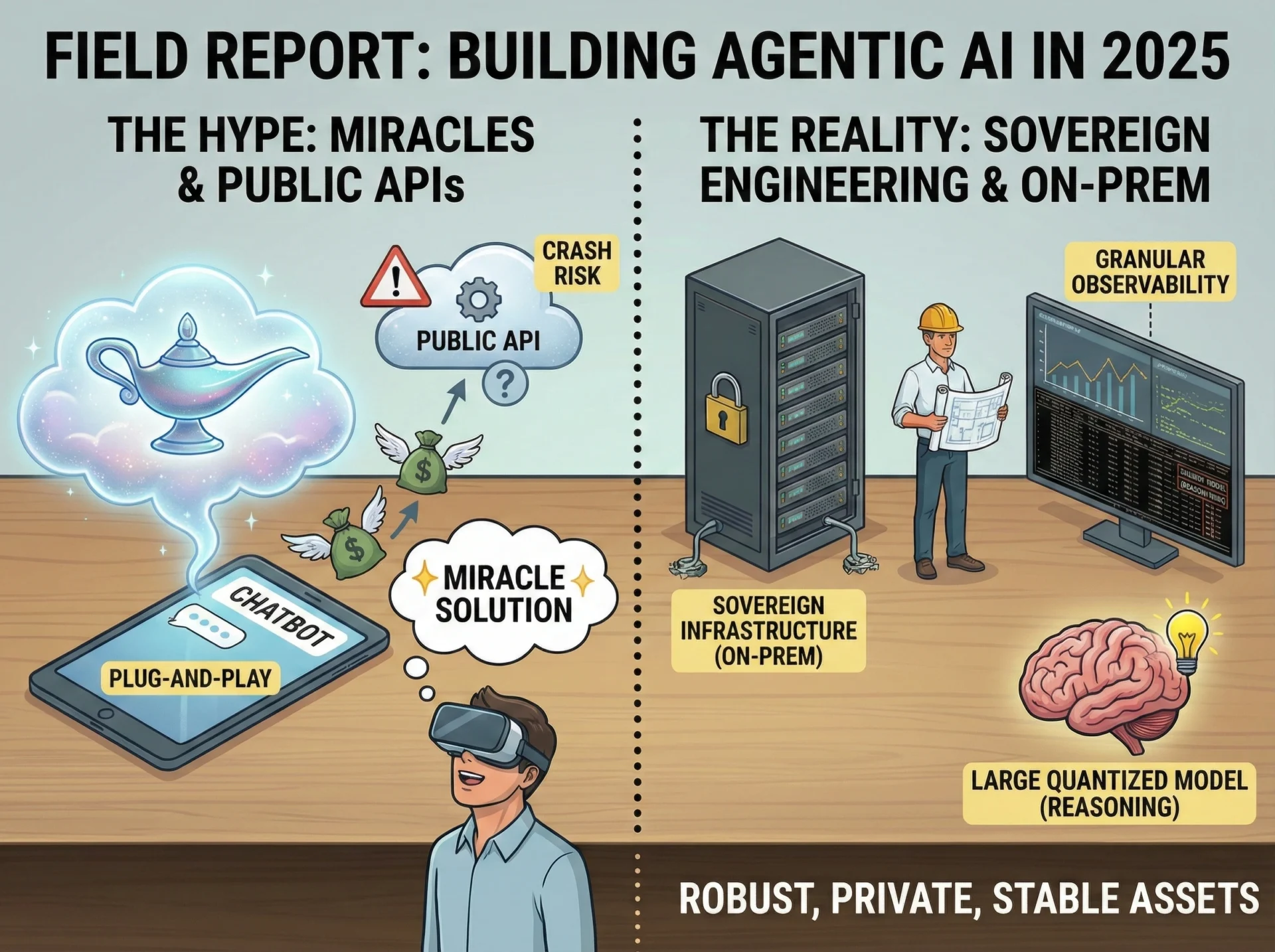
Het verhaal rond “Agentic AI” in 2025 wordt gekenmerkt door een scherp contrast tussen marktverwachtingen en de technische realiteit. Terwijl het grote publiek, gewend geraakt aan het gemak van ChatGPT, “wonderen” en directe integratie verwacht, is de realiteit van het bouwen van autonome agenten voor bedrijfsprocessen een discipline van rigoureuze engineering, diepgaande architecturale planning en infrastructuur-soevereiniteit.
Dit rapport beschrijft de uitdagingen en methodologieën die wij zijn tegengekomen bij het implementeren van maatwerk AI-agenten op eigen infrastructuur (on-premise). In tegenstelling tot het merendeel van de markt, dat vertrouwt op volatiele publieke API’s, richt onze aanpak zich op Sovereign AI (Soevereine AI): het lokaal draaien van modulaire, op maat gemaakte oplossingen. Deze strategie elimineert de risico’s van API-crashes, “stille updates” die prompts breken en onvoorspelbare prijsstijgingen. Zo garanderen we dat de oplossingen van onze klanten op de lange termijn robuust, privé en kostenefficiënt blijven.
1. De Verwachtingskloof en de Noodzaak voor Maatwerk
1.1 De Mythe van het Wonder vs. Technische Realiteit
Een veelvoorkomende uitdaging in 2025 is de “over-verwachting” van AI-capaciteiten. Klanten benaderen Agentic AI vaak met de mindset van een chatbot-gebruiker en verwachten een plug-and-play oplossing die “magisch” en direct uit de doos hun volledige ERP-systeem kan navigeren.
- De Realiteit: Een AI-agent is geen wonder; het is een complex softwaresysteem dat gedefinieerde grenzen vereist.
- De Oplossing: Wij bouwen alles modulair. Door de architectuur op te bouwen uit componenten, zorgen we ervoor dat wanneer een klant opschaalt of nieuwe use-cases identificeert (bijv. uitbreiden van support-ticketing naar voorraadbeheer), we nieuwe “cognitieve modules” kunnen integreren zonder het kernsysteem te herschrijven. Deze modulariteit is essentieel voor levensvatbaarheid op lange termijn.
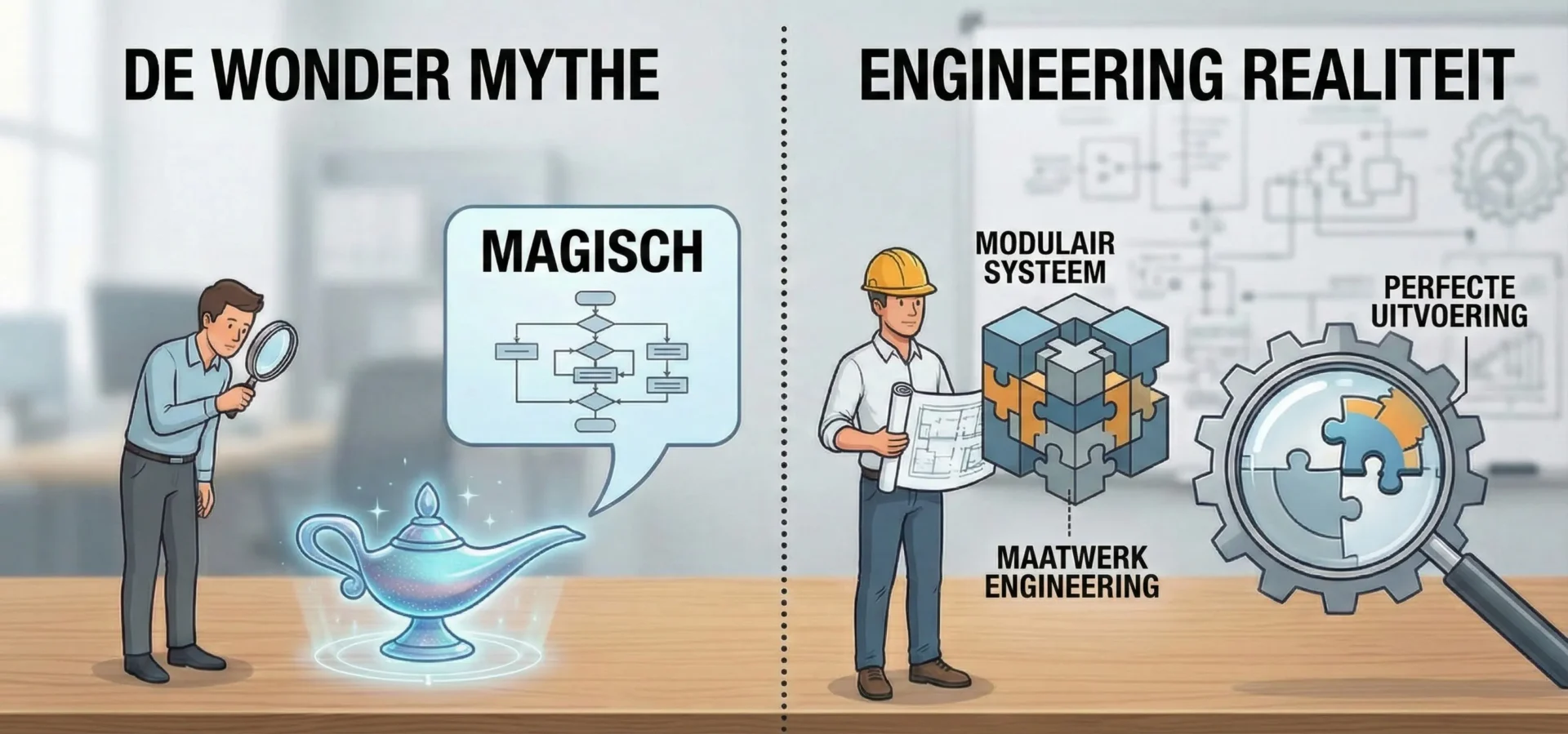
1.2 Het Falen van “Globale” Oplossingen
We hebben vastgesteld dat het bouwen van een “globaal” product dat voor elke klant probeert te werken, een valkuil is. Generieke agenten missen de nuances van specifieke bedrijfsworkflows, wat leidt tot fragiele prestaties en een hoge overhead aan support.
- Engineering op Maat: Succes vereist het analyseren van de volledige workflow van de klant, wat vaak gepaard gaat met vergaderingen op locatie en deep dives in hun datastructuren. Een oplossing die is afgestemd op de specifieke eigenaardigheden van de data van een cliënt, zal altijd beter presteren dan een generiek “one-size-fits-all” model.
- Spot-On Uitvoering: Door de scope van de agent te beperken tot een maatwerkomgeving, verkleinen we het risico op hallucinaties en logische fouten. Dit zorgt ervoor dat de oplossing “spot on” is, in plaats van slechts “redelijk oké”.
2. De Economie van Agentic AI
2.1 De Kosten van Discovery
Omdat bestaande AI-agenten niet simpelweg “geïmplementeerd” kunnen worden als een standaard softwarebibliotheek, vereist elk project een aparte analysefase.
- Discovery-fase: We investeren aanzienlijke tijd in pre-development analyse. Dit omvat meerdere sessies om de “real life” situatie van de operationele processen van de klant in kaart te brengen.
- Kostenrealiteit: Zoals gedetailleerd in industrie-analyses, omvatten de kosten van maatwerk agent-ontwikkeling verborgen factoren die verder gaan dan alleen coderen, waaronder het voorbereiden van datasets, architectuurontwerp en uitgebreide testing.
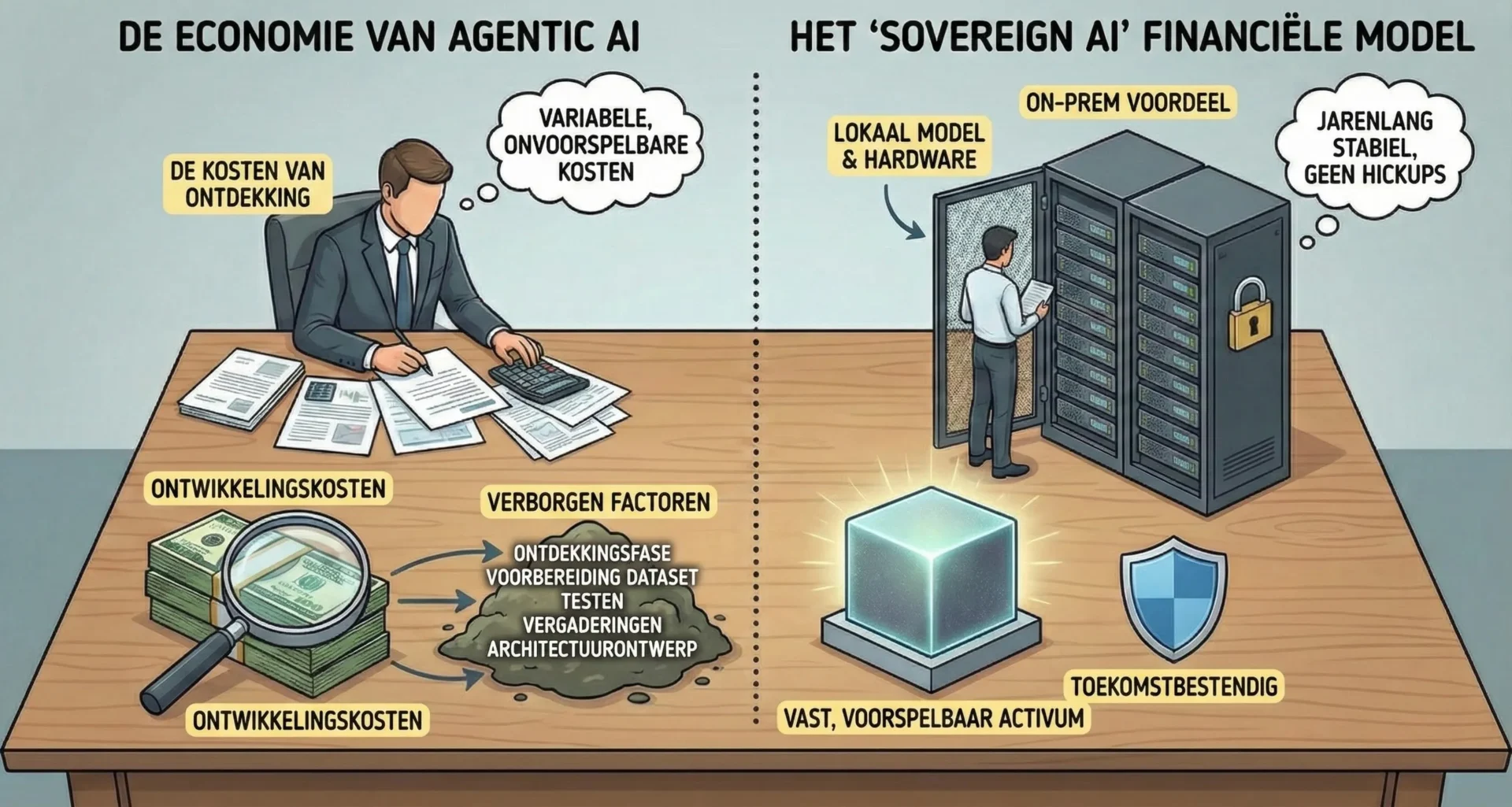
2.2 Het “Sovereign AI” Financieel Model
Wij maken geen gebruik van de API’s van grote aanbieders (OpenAI, Anthropic, etc.). Vertrouwen op externe API’s introduceert existentiële bedrijfsrisico’s:
- Volatiliteit: Zal de API-prijs plotseling verdrievoudigen?
- Betrouwbaarheid: Zal de API crashen tijdens piekuren?
- Drift: Zal een “stille model-update” onze prompts van de ene op de andere dag breken?
Het On-Premise Voordeel: Door alles lokaal te trainen en te draaien (On-Prem), zetten we variabele, onvoorspelbare kosten om in vaste, voorspelbare activa.
- Toekomstbestendig: Een lokaal model gecombineerd met eigen hardware doet zijn werk jarenlang effectief zonder haperingen. Het wordt niet “dommer” omdat het “oud” is, noch kost het meer om te draaien in 2027 dan in 2025. Het is een stabiel bedrijfsmiddel.
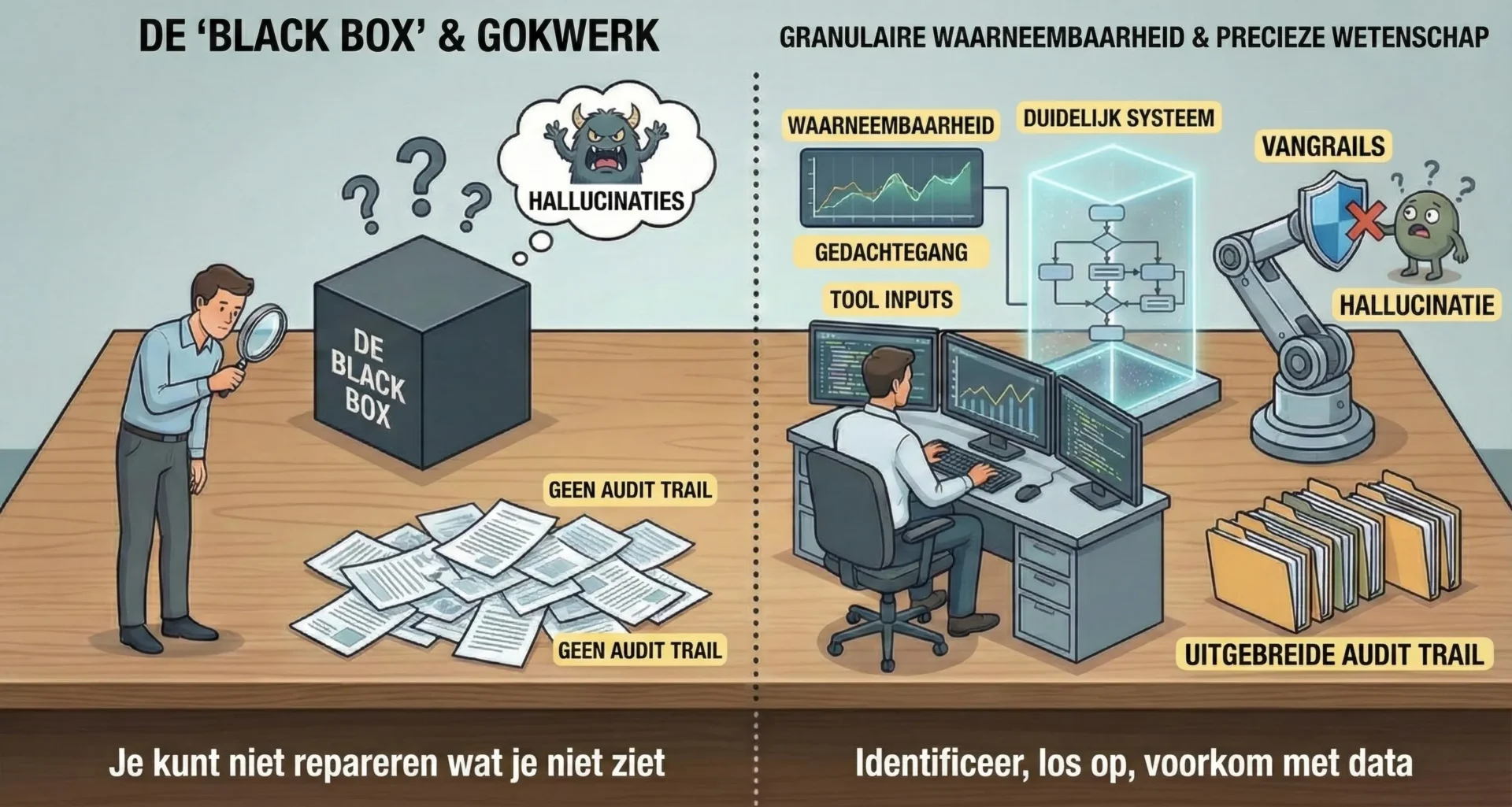
3. Observability, Debugging en Hallucinaties
Je kunt niet repareren wat je niet kunt zien. Wij zijn trots op het leveren van “uitstekend werkende oplossingen”, wat granulaire observability (waarneembaarheid) vereist.
3.1 Het Volgen van de “Black Box”
We gebruiken meerdere tools om het besluitvormingsproces van het LLM (Large Language Model) uitgebreid te volgen. Het debuggen van een agentic loop vereist inzicht in de exacte “Chain of Thought” (gedachtegang) en de tool-inputs die tot een specifieke actie hebben geleid.
- Waarom we dit doen: Het stelt ons in staat om precies aan te wijzen waar een agent vastliep in een lus of faalde om de juiste context op te halen, waardoor debuggen verandert van gissen in een exacte wetenschap.
3.2 Het Beheersen van Hallucinaties
Hallucinaties zijn een onvermijdelijkheid die beheerd moet worden. Wij loggen alles. Door een uitgebreid auditspoor bij te houden van elke input, gedachte en output, kunnen we:
- Traceren: Patronen identificeren waarbij het model consistent confabuleert.
- Oplossen: De systeemprompt aanpassen of het model fine-tunen om deze specifieke faalmodi te elimineren.
- Voorkomen: “Guardrail”-classifiers implementeren die hallucinerende output blokkeren voordat deze de gebruiker bereikt.
3.3 Metadata Strategie voor Agentic Search
Om agentic search te laten werken, is “ruwe tekst” onvoldoende. We zorgen ervoor dat we uitgebreide metadata opslaan naast de vector embeddings.
- Contextuele Verankering: Een agent die een contract analyseert, moet de datum, auteur, versie en afdeling kennen. Zonder deze metadata zoekt de agent blindelings. We bouwen onze data-ingestie pipelines zo dat deze context automatisch wordt vastgelegd, zodat de agent niet alleen “vergelijkbare tekst” ophaalt, maar ook “het juiste document”.
4. De Cognitielaag: Modellen en Training
4.1 Fine-Tuning is Niet Optioneel
We testen open-source modellen uitgebreid, maar ze voldoen zelden “out of the box” aan onze specifieke verwachtingen.
- De Realiteit: Om betrouwbaarheid van productiekwaliteit te bereiken, moeten we modellen bijna altijd fine-tunen op de specifieke data van de klant. Dit brengt de “stem” en logica van het model in lijn met de daadwerkelijke bedrijfsregels van de klant.
4.2 Visuele Modellen: Trainen vanaf de Basis
Voor visie-gerelateerde projecten is fine-tuning vaak onvoldoende. We trainen modellen regelmatig from scratch op de propriëtaire visuele data van de klant (bijv. fabricagefouten, document lay-outs). Dit zorgt ervoor dat het model de specifieke visuele kenmerken leert die relevant zijn voor de cliënt, in plaats van te vertrouwen op generieke kenmerken die getraind zijn op internetdata.

4.3 Redeneermodellen en Benchmarks
We hebben ondervonden dat redeneermodellen (zoals DeepSeek R1 of vergelijkbare logica-zware architecturen) absoluut de betere keuze zijn voor complexe agentic workflows.
- Benchmarks zeggen niet alles: Een model kan hoog scoren op een generieke benchmark (zoals MMLU), maar de kleinste wijziging in onze prompting of workflow kan een totaal ander effect genereren. Uitgebreide interne testen spreken publieke leaderboards vaak tegen.
5. Hardware Realiteiten: De VRAM-bottleneck
5.1 De Geheugen/Context Afweging
Het lokaal draaien van “Redeneermodellen” komt met aanzienlijke kanttekeningen, voornamelijk wat betreft hardwarevereisten.
- De “Buffer” Noodzaak: Context is duur. Het analyseren van één enkele mailwisseling van 50 e-mails kan gigabytes aan geheugen verbruiken puur voor de KV-cache.
- De Faalmodus: Als deze geheugenbuffer niet beschikbaar is, krijgt het systeem een Out-Of-Memory (OOM) foutmelding, of zijn we gedwongen context in te korten. Wanneer context wegvalt, daalt de nauwkeurigheid en “faalt de AI-agent”.
5.2 Kwantisatie: Groter is Beter
We hebben empirisch vastgesteld dat parameter-aantal wint van precisie.
- De Regel: Een groot, gekwantiseerd model, bijvoorbeeld een 72B parameter model gekwantiseerd naar FP8 (of zelfs lager), genereert vaak veel betere redeneerresultaten dan een kleiner 8B model dat ongekwantiseerd draait (BF16).
- Waarom: Het grotere model bezit een dieper “wereldmodel” en logisch vermogen dat kwantisatie overleeft, terwijl het kleinere model, zelfs bij hoge precisie, de cognitieve diepgang mist om complexe taken uit te voeren.
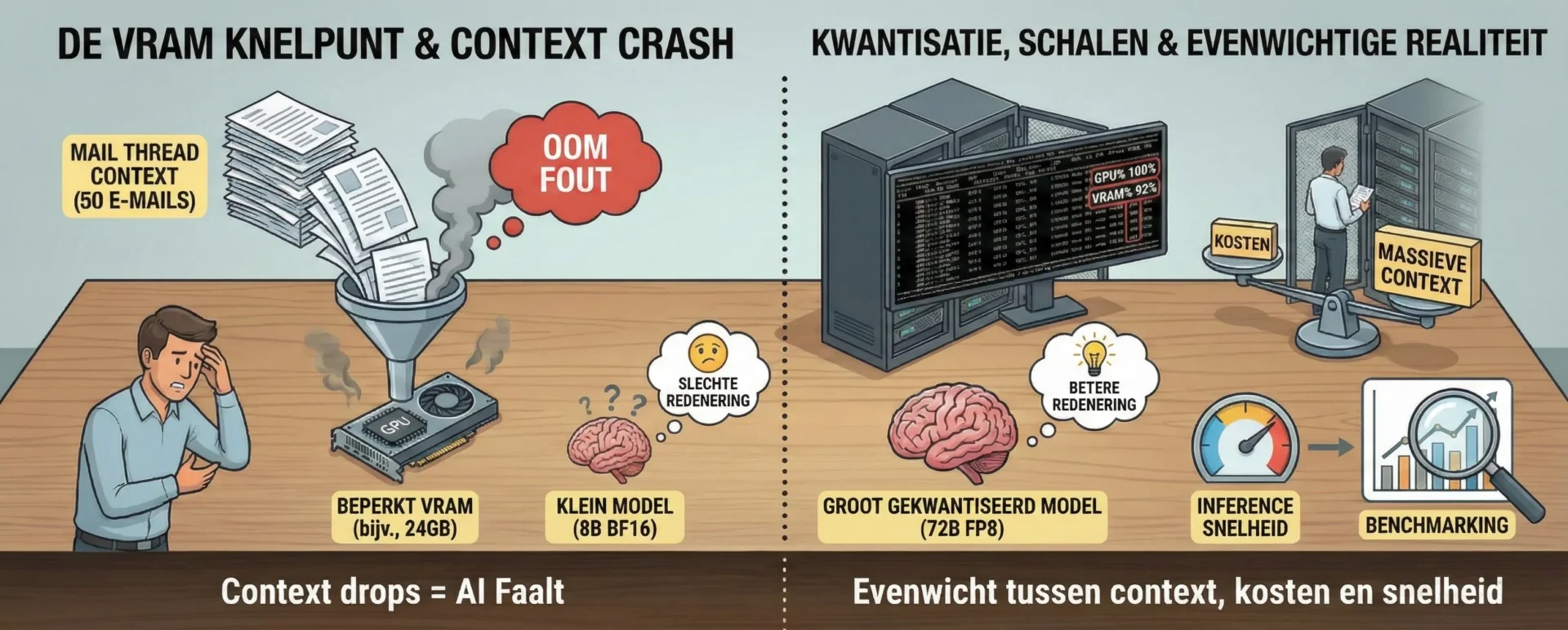
5.3 Schaling en Kosten
Hoewel we dure datacenter GPU’s (B200s/MI355X) met enorm geheugen kunnen aanschaffen, zijn deze vaak onbetaalbaar voor middelgrote (of zelfs grotere) bedrijven.
- De Uitdaging: We moeten voortdurend balanceren tussen de behoefte aan enorme context (voor betrouwbaarheid) en de budgettaire beperkingen van on-premise hardware.
- Inferentiesnelheid vs. Nauwkeurigheid: We testen gekwantiseerde versies uitgebreid om te zien of we de inferentie kunnen versnellen en geheugen kunnen besparen zonder verlies van nauwkeurigheid. Het werkt niet zomaar “vanzelf”; het vereist rigoureuze benchmarking per use-case.
Conclusie: De Constante Evolutie
De markt verandert razendsnel. Nieuwe kwantisatie-formaten, nieuwe open-source modellen en nieuwe agentic frameworks verschijnen dagelijks.
- Onze Toewijding: We moeten bijblijven. We testen en verbeteren onze workflows continu om ervoor te zorgen dat onze klanten niet achteropraken.
- De Positieve Kant: Ondanks de uitdagingen, de hardwarebeperkingen, het opschonen van data en het tracken van hallucinaties, houden we ervan. We bouwen systemen die echte, soevereine automatisering bieden, vrij van de grillen van de grote AI-providers.
Klaar om uw Soevereine AI-personeelsbestand te bouwen? Als u op zoek bent naar een partner om deze uitdagingen het hoofd te bieden en een op maat gemaakte, on-premise oplossing te bouwen die echt uw eigendom is, staan wij voor u klaar.