Building the Engine for the AI Race: The 4-Month Path to NVIDIA GB300 NVL72 Power
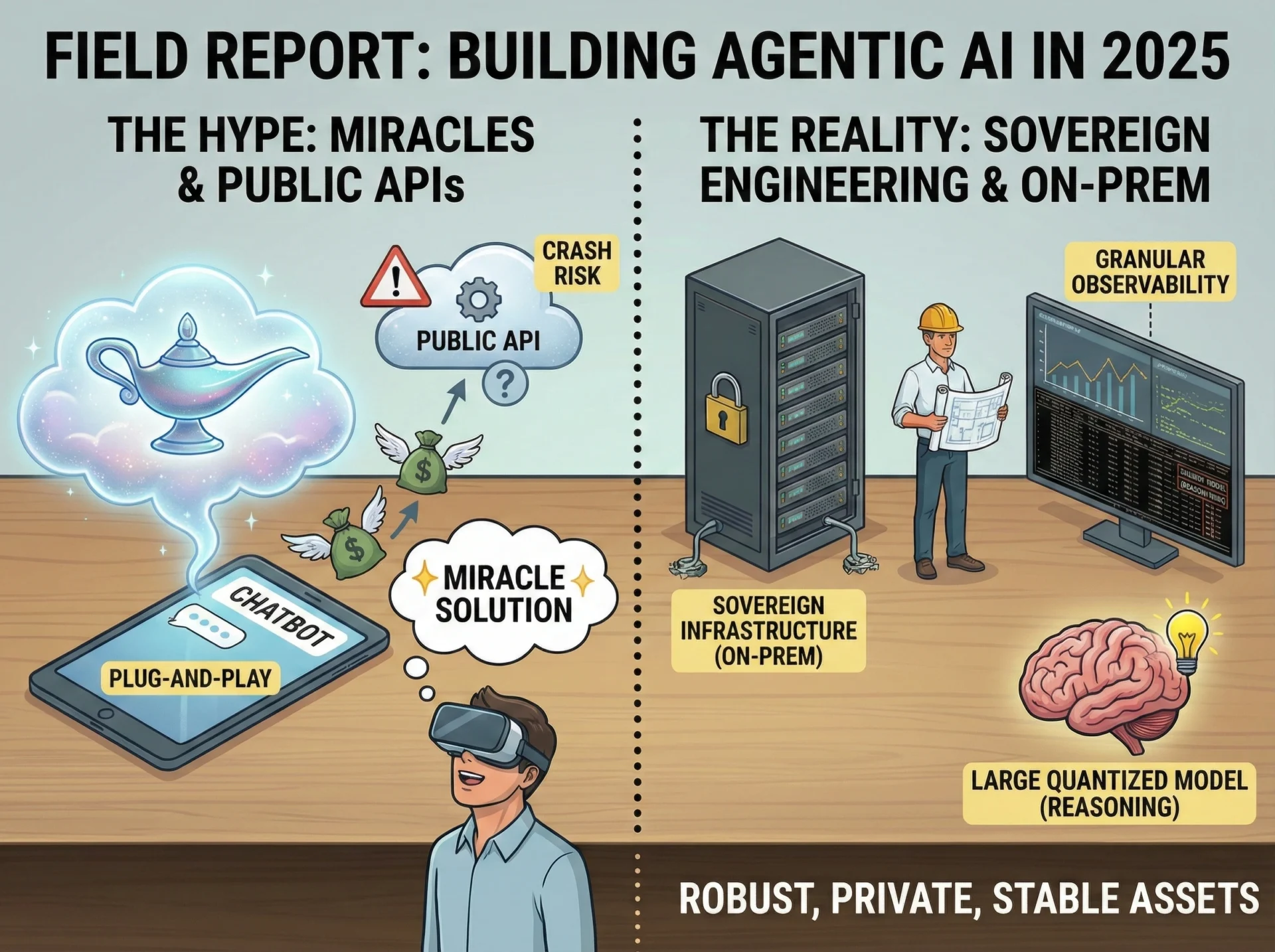
In artificial intelligence infrastructure, speed is the foundation of competitive differentiation. From model training velocity to inference latency, every millisecond matters. But before any workload executes, there is a critical prerequisite that often determines success or failure: time to market.
Traditional builds typically require 18–24 months. In the current AI cycle, that is simply too slow. We have refined a modular pipeline to achieve operational status within just 4 months, delivering a turnkey facility specifically architected for the NVIDIA GB300 NVL72.
The Challenge: Hosting a Beast
The NVIDIA GB300 NVL72 integrates 72 NVIDIA Blackwell Ultra GPUs and 36 Arm-based NVIDIA Grace CPUs in a fully liquid-cooled, rack-scale architecture.
This represents a fundamental shift in data center infrastructure requirements. We aren’t just powering servers; we are powering a massive, dense cluster where each rack draws approximately 120 kW under typical loads, potentially reaching 150 kW peak power during intensive computational workloads.
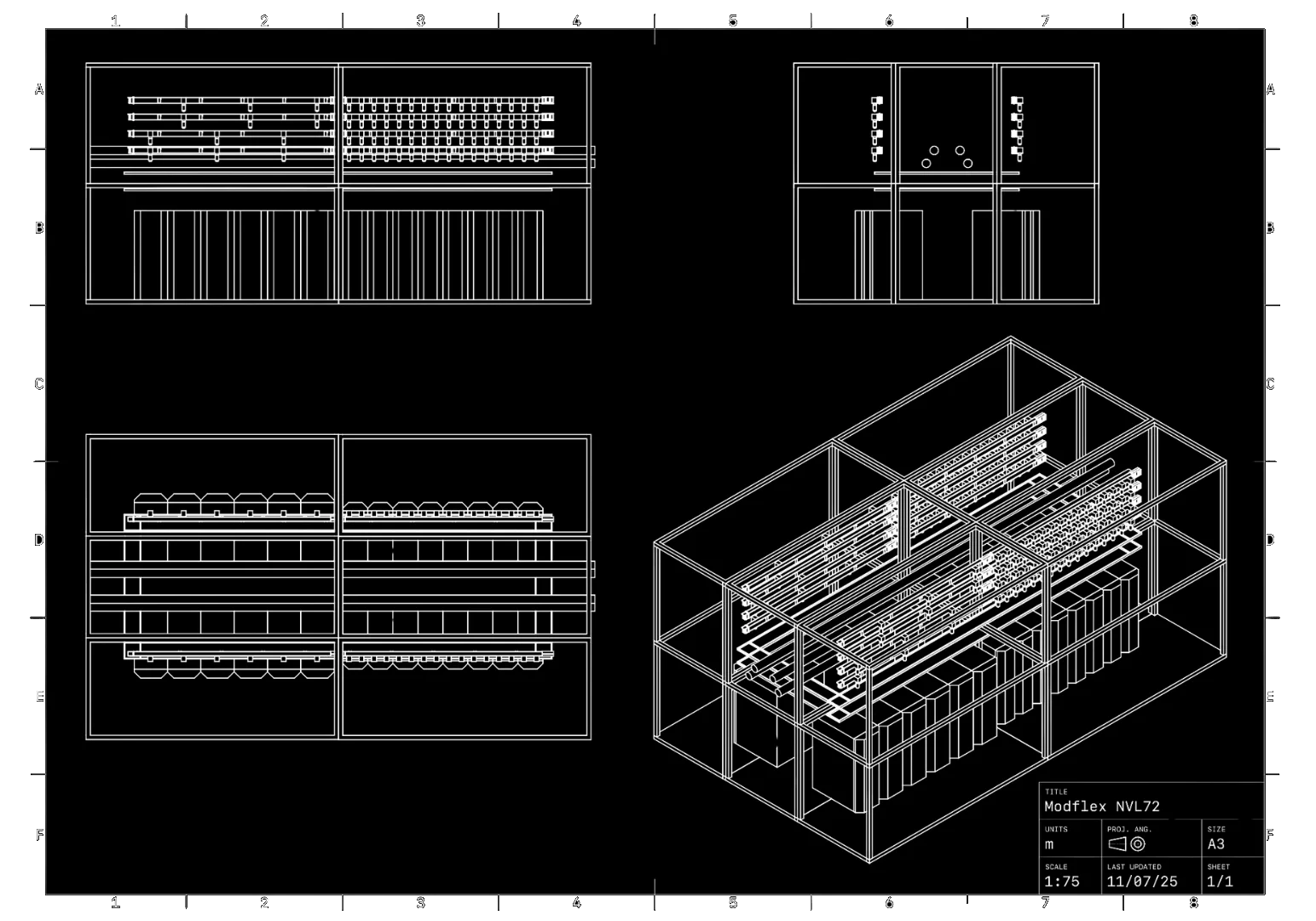
Architecture Overview: Precision at Scale
To accommodate this density, our facility uses a layout optimized for the specific footprint of the GB300.
Our facility accommodates:
- 16x 600mm GB300 NVL72 racks (primary compute infrastructure)
- 12x 800mm auxiliary racks distributed as:
- 5 racks for network infrastructure
- 5 racks for management and storage systems
- 2 racks for future expansion
Power Distribution: The “4-Makes-3” Architecture
The extreme power density of GB300 NVL72 systems, 150 kW peak per rack, necessitates an enterprise-grade power distribution strategy.
We’ve implemented the NVIDIA reference design 4-makes-3 busbar configuration, where four independent 1 MW busbars provide power through an $N=3+1$ redundancy model.
This architecture delivers:
- Full concurrency maintainability: Any single busbar can be taken offline for maintenance without service interruption.
- True redundancy: Three busbars can support full operational load.
- Total power envelope: Approximately 2.8 MW (variable based on storage configuration requirements).
Additionally, the GB300 NVL72 incorporates advanced power supply units with energy storage that reduce peak grid demand by up to 30% by smoothing power spikes from AI workloads.
Advanced Thermal Management: Hybrid Cooling
Direct liquid cooling can extract up to 80% of the heat of the SU, with the remaining heat requiring alternative dissipation methods. We’ve engineered a hybrid thermal management system optimized for computational efficiency and modularity.
Primary Cooling Strategy
- GB300 NVL72 Compute Racks:
- 80% thermal load managed via Direct Liquid Cooling (DLC).
- 20% residual heat captured through Rear Door Heat Exchangers (RDHx) or CRAH units.
- DLC operates by establishing direct contact between heat-generating components and cold plates connected to coolant-filled tubes.
- Auxiliary Infrastructure (Network/Management/Storage):
- 100% RDHx cooling baseline.
- Seamless transition path to DLC as thermal requirements evolve.
The Critical Loops
- Secondary Loop (CDUs): In-rack Coolant Distribution Units provide real-time monitoring of flow rates, temperatures, and pressure differentials, along with comprehensive leak detection.
- Primary Loop (Heat Rejection): The primary thermal rejection system comprises three 1,125 kW Chiller/Dry coolers operating in an $N=2+1$ configuration. This eliminates water consumption typical in traditional cooling approaches.
Structural & Environmental Design
The core IT environment utilizes open steel frame construction systems, creating a secure and controlled environment featuring:
- Fire suppression: Argon-based systems (clean agent, non-conductive, oxygen-displacement mechanism).
- Air purification: HEPA filtration maintaining ISO Class 8 cleanroom standards.
- Access control: Biometric authentication and mantrap configurations.
Scalability: Architected for Growth
One of the most critical advantages of our modular approach is seamless scalability that aligns precisely with NVIDIA’s reference architecture. Our modular data centers can be deployed to support these standardized scaling increments:
Deployment Configurations:
- 1 SU (16 racks, 1.152 GPU) – Single scalable unit baseline deployment
- 2 SU (32 racks, 2.304 GPU) – Initial production scale
- 4 SU (64 racks, 4.608 GPU) – Enterprise-grade cluster
- 7 SU (112 racks, 8.064 GPU) – Large-scale training facility
- 8 SU (128 racks, 9.216 GPU) – High-density AI factory
- 9 SU (144 racks, 10.368 GPU) – High-density AI factory
- 18 SU (288 racks, 20.736 GPU) – Hyperscale deployment
- 36 SU (576 racks, 41.472 GPU) – Frontier-scale supercomputing cluster

Conclusion: Engineering for Tomorrow
The GB300 NVL72 delivers approximately 140 kW rack-scale unit providing 1.1 exaFLOPS of FP4 computing, computational density that fundamentally redefines data center requirements.
Our 4-month deployment cycle represents the convergence of advanced thermal engineering, redundant power architectures, and purpose-optimized structural design. The future of AI infrastructure is modular, redundant, and optimized for extreme density It is also operational in sixteen weeks.